Today we’re excited to share our Twilio integration in Daily Bots, where developers build adaptive conversational voice AI on the world’s leading global real-time infrastructure and open source SDKs.
Daily Bots is architected to give enterprises and developers the flexibility they need as they build adaptive voice AI. Now you can use your Twilio numbers and voice workflows directly with real-time conversational voice AI and LLM workflows powered by Daily Bots.
- With this release, Daily Bots natively supports Twilio WebSockets.
- Right in your Daily Bots dashboard (or via REST API), developers can create real-time voice AI agents configured with a TwiML code output.
- Attach the generated TwiML code output to a Twilio Bin and use it in any Twilio workflow such as Twilio Flex, Twilio Studio, and IVR. Support both dial-in and dial-out.
Daily Bots-powered agents are state-of-the-art, talking naturally in conversation, with ultra low latency, as they retrieve structured data using any LLM, for tasks like scheduling appointments, answering questions back-and-forth about a policy, completing intake, and triaging and routing more effectively.
Agents can be spun up and down as needed, to support goals like dynamic, streamlined operations and happier, engaged customers.
Start here, to try it out. Below we discuss real-time AI agents in voice workflows, how Daily Bots enables voice AI, and how the integration works.
Improving telephony workflows
Telephony is a bedrock of customer communications and omnichannel UX. Yet companies face what McKinsey calls a “a perfect storm of challenges,” including increasing call volumes and staffing issues.
Meanwhile, today’s customers are vocal about hold times, phone trees, voice mail, and unhappy experiences.
Over the last year, step function improvements in a suite of AI technologies — spanning orchestration, function calling, LLM and voice models, and more — have enabled agents that can bring AI’s structured data insights into real-time conversation.
Learn how Daily Bots brings state-of-the-art conversational abilities and flexibility:
- Avoid vendor lock in. The Daily Bots hosted offering is built on top of open source client SDKs and Pipecat, the fastest growing Open Source voice AI framework.
- Better customize for enterprise workflows. Daily Bots leverages function calling, tool use, and structured data generation. Integrate with headless knowledge base APIs and existing back-end systems.
- Run on proven infrastructure. We have managed infrastructure at global scale since 2016, with 99.99% uptime across 75 points of presence, around the world with SOC 2 Type 2 certification and HIPAA and GDPR compliance. Daily’s edge network delivers 13ms median first-hop latency to a coverage footprint of 5 billion end users.
- Deploy into your VPCs or private networks as needed. Daily can help you with on premises or VPC infrastructure if your use case requires. Our product and engineering leadership has extensive experience working with customers in high-security contexts.
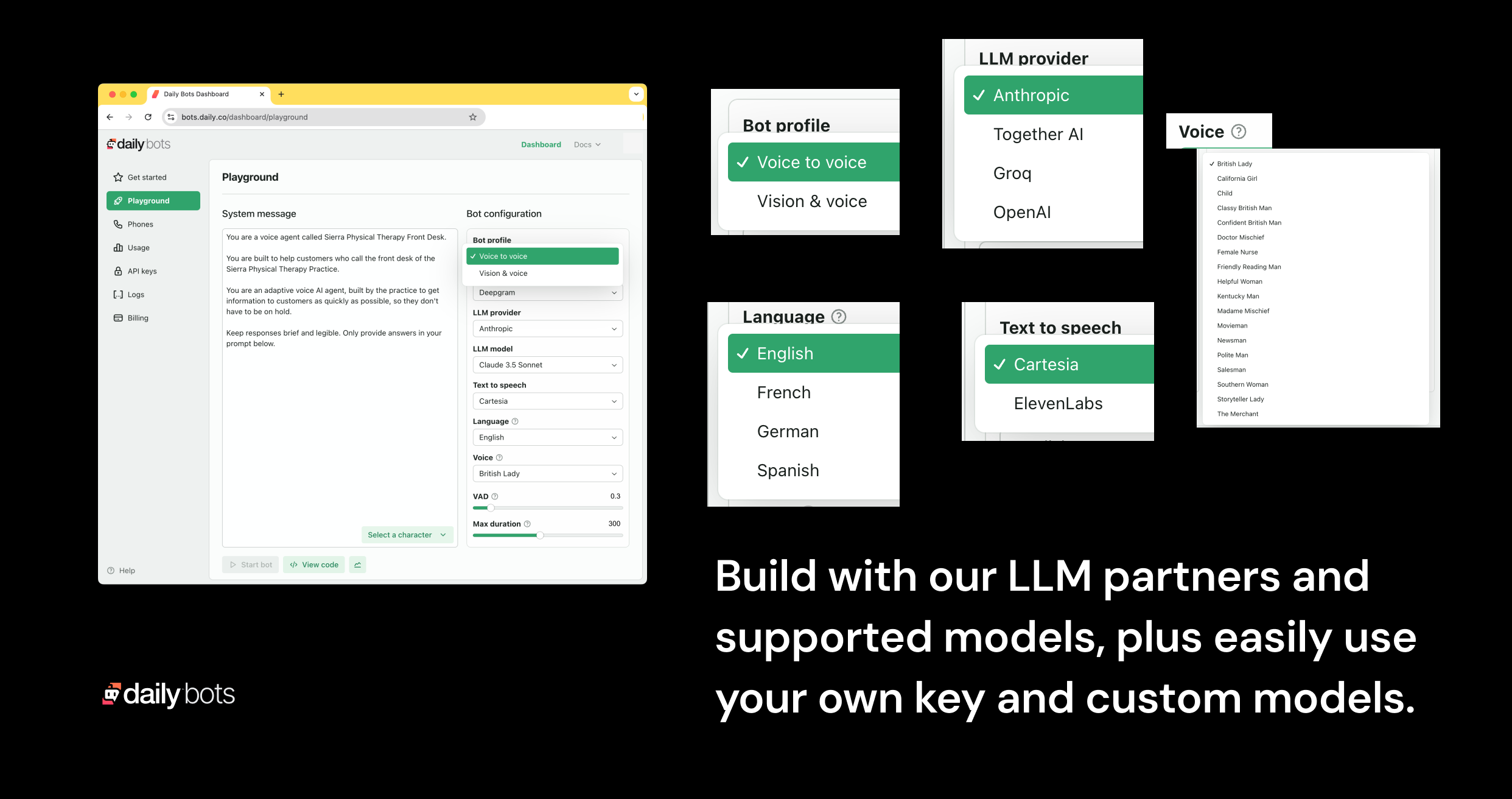
Right in your dashboard, you can build unified voice-to-voice applications with any LLM. Daily’s modular approach provides both a best-in-class developer experience and simple, transparent billing and pricing. Our partners include leading AI model providers including Anthropic, Cartesia, Deepgram, OpenAI and Together AI; or you can bring your own keys and use your preferred models (including custom models).
With this enablement, enterprise customers can flexibly use Daily Bots across their technology stack. Today’s release furthers that goal, allowing you to leverage your existing Twilio Voice assets together with the Daily Bots adaptive voice feature set.
Supporting Twilio Voice Workflows, building on Twilio WebSockets
Twilio is the leader in programmable voice, supporting over 10 million developers from startups to the enterprise. It has developed a complete suite of voice products — like Twilio Flex, Twilio Studio, and hosted Twilio apps — which lets its customers build across use cases like IVR, alerts and notifications, call tracking, and more.
Telephony is integral to voice conversations, and Daily Bots has always supported a full suite of telephone and SIP features. With this release, your customers can dial your Twilio number and talk to a Daily Bot. Use cases we have seen include:
- Business messaging platforms. A platform uses Twilio Studio to provision phone numbers for trades and services. When a customer dials the numbers, instead of being connected to a front desk or getting voice mail, they immediately talk to an AI agent, who can complete scheduling. The agent is able to ask questions in a conversation back-and-forth with the customer. Based on some qualifying questions, the agent can book an appointment immediately and/or route the customer for elevated support.
- Professional services platforms. To help patients achieve better outcomes after care, a provider's office pings them across channels, to check in. While outreach like SMS can remind a patient to call, an AI agent can handle this much more flexibly. The AI agent calls the patient and based on responses in conversation, can flag the patient for further follow up.
- Industries like financial services that build Twilio workflows in conjunction with Google Dialogflow extensively are transitioning previous-generation NLP workflows to AI conversational voice. Today’s LLMs deliver higher customer satisfaction, percentage of calls handled without human intervention, and call deflection metrics, at lower cost than older call center technologies.
You can learn more about how to build all of these things in the Daily Bots docs.
How it works
Daily Bots generates Twilio TwiML code for you. TwiML is the Twilio Markup Language. Developers use TwiML to build Twilio workflows. You can create a Daily Bots voice AI session wherever you use TwiML.
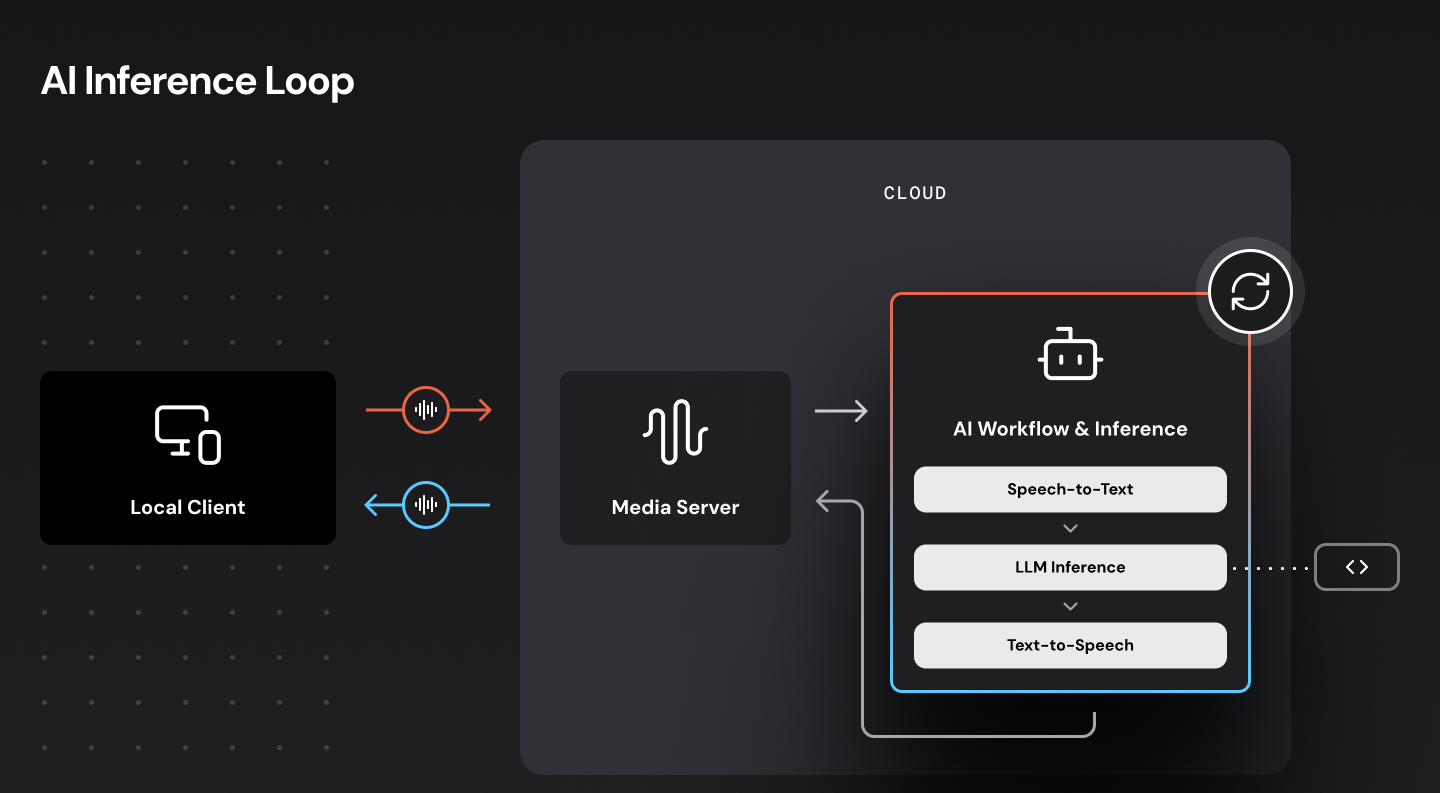
WebRTC and WebSockets infrastructure
Daily Bots supports both WebRTC and WebSockets depending on your use case:
- Daily Bots uses WebSockets for Twilio – and other telephony and SIP – connectivity. Twilio’s WebSockets implementation is robust and delivers good performance for two-way audio streams over server-to-server network connections.
- Daily Bots sessions can also run on top of Daily’s global WebRTC infrastructure. WebRTC provides lower-latency, higher-bandwidth, higher-quality connectivity and is the best protocol for delivering audio directly to end-user devices such as web browsers and mobile phones. Daily Bots sessions can be accessed by Daily WebRTC transport, PSTN telephone dial-in, telephone dial-out, Web browser apps, and native apps on iOS, Android, and other platforms. WebRTC also supports video and multi-participant real-time AI applications.
Developer Workflow
To set up a Twilio + Daily Bots integration:
- Configure a Daily Bot using the Daily Bots dashboard. This generates both a Daily Bot configuration and TwiML code.
- Open your Twilio console and create a TwiML Bin. Save the bin and assign it to a phone number in the Twilio console.
- You can create a Daily Bot session in any of your Twilio workflows, using this TwiML code.
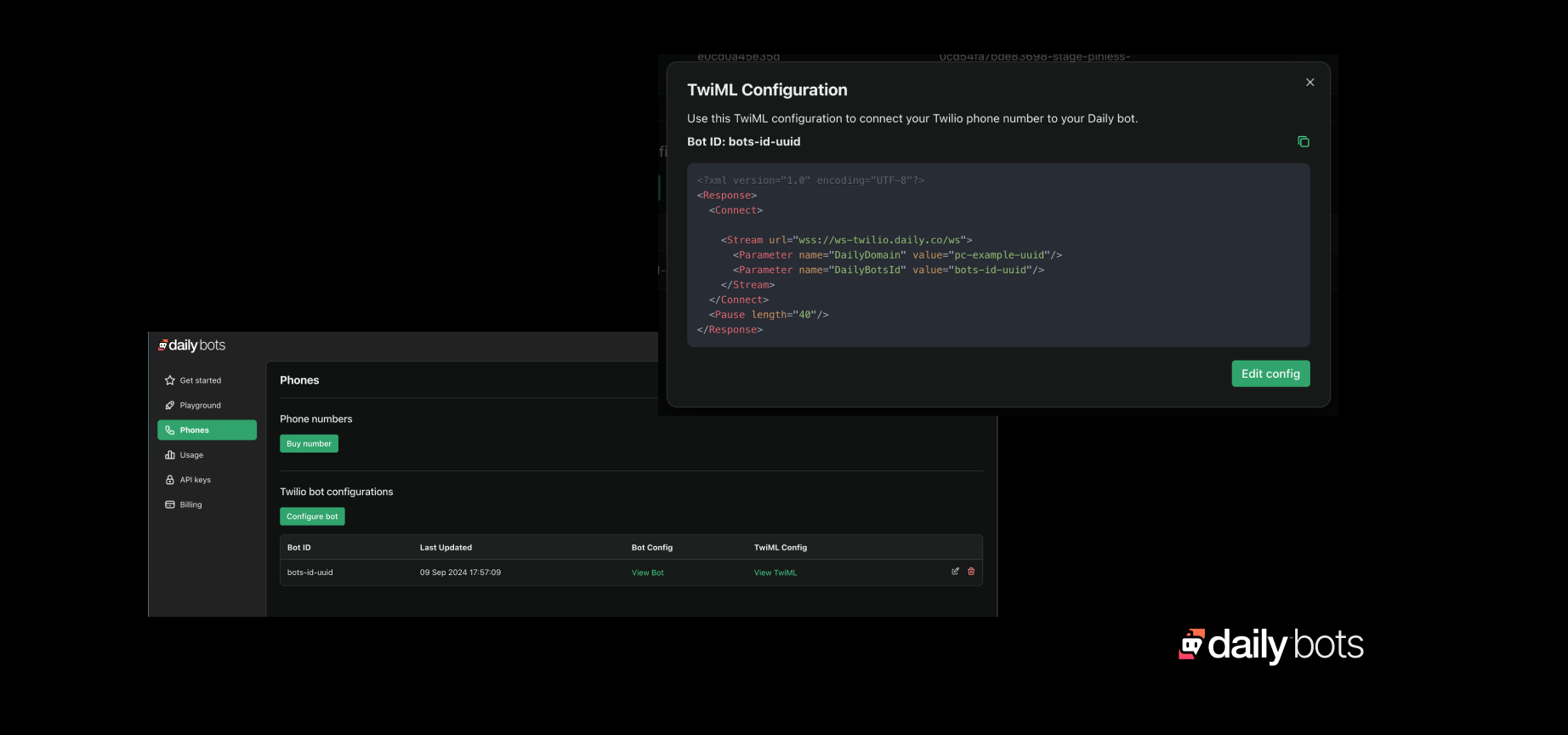
For dial-in, calling the Twilio number automatically routes to the corresponding Daily Bot.
For dial-out, use the Twilio REST API or Twilio CLI to call the target phone number. Learn more here.
Get Started
Given the centrality of voice, leveraging the benefits of real-time conversational voice AI is a key consideration for our enterprise customers and developer community.
Get started here. Below are a few more links if you'd like to dive in more. We're excited to partner with you.
- Sign up, $10 in credits, https://bots.daily.co
- Visit the developer docs
- Contact sales for enterprise needs
- Watch a video on how to configure Daily Bots and Twilio Voice
Follow us on social. Our technical cofounder Kwindla regularly posts about real-time conversational voice AI. You can follow Daily on LinkedIn and Twitter.
]]>
Today we’re sharing Daily Bots, a hosted AI bots platform.
Developers can ship voice-to-voice AI with any LLM; build with Open Source SDKs; and run on Daily’s real-time global infrastructure:
- Create AI agents that talk naturally.
- Design voice-to-voice AI flexibly, with leading commercial and open models. We’ve partnered with Anthropic, Cartesia, Deepgram, and Together AI. You can also use any LLM that supports OpenAI-compatible APIs.
- Build ultra low latency experiences for desktop, mobile, and telephone.
- Use the leading Open Source tooling for voice-to-voice and multimodal video AI. Daily Bots implements the RTVI standard for real-time inference, and is built on the Pipecat server-side framework.
- Launch quickly and scale on Daily’s global WebRTC infrastructure.
In this post, we’ll talk about why we built Daily Bots and what it does; how we're excited to work with our partners; and also some of the fun demos you can play with.
If you’d like to jump straight in, here are docs and demos — our playground demo with configurable LLMs; function calling demo and vision with Anthropic; and iOS and Android. Sign up here (with a $10 credit during launch week).
Why Daily Bots
At Daily, we’ve been building real-time audio and video infrastructure since 2016. Our customers have been developers building conversational experiences – it started with people talking to each other.
Now, with generative AI, the definition of conversational experiences has expanded. Today’s Large Language Models are very good at open-ended conversations. They can follow scripts and perform multi-step tasks. They can call out to external systems and APIs.
Voice-driven LLM workflows are starting to have a big impact in healthcare and education. LLMs are improving the customer support experience and enterprise workflows. Virtual characters will transform video games and entertainment. And this is just the start of the impact of AI.
Building experiences in which humans can have useful, natural, real-time conversations with AI models involves:
- Choosing and writing code for the right generative AI models for your specific use case.
- Orchestrating the human -> AI -> human conversation loop, incorporating prompting, state management, data flow between models, and calling out to external systems.
- Standing up both audio/video infrastructure and AI/orchestration infrastructure – service discovery, routing, autoscaling, fault tolerance, observability.
- Having good client SDKs for all the platforms you need to support.
Over the past year and a half, as we’ve been helping our customers stand up new AI-powered real-time features, we’ve put together a complete set of tools that check all the boxes above.
We’ve rolled these tools and best practices into two big Open Source projects: Pipecat for server-side AI orchestration and the RTVI open standard for real-time inference clients. These are truly vendor neutral efforts, with a growing community and contributors from a wide range of stakeholders.
Now we’re filling another gap in the voice-to-voice and real-time ecosystem with Daily Bots.
- Daily Bots lets you run your RTVI/Pipecat AI agents end-to-end on Daily’s infrastructure.
- Start a real-time AI session with a single call to /api/v1/bots/start. Launch fast. Scale without limits. If your needs evolve beyond Daily Bots, you can take your code to another platform or stand up your own infrastructure.
AI that talks naturally
Human conversation is complicated!
We interrupt each other. We know when someone finishes speaking and expects us to talk. We change topics and go off on tangents.
And, most of all, we almost always respond quickly. Long pauses make conversations feel so unnatural that most people will just opt out. It’s critical to have voice-to-voice response times faster than 1 second. (Faster than 800ms is better!)
Daily Bots implements best practices for all of the hard, low-level challenges that voice AI product teams face. With a few lines of code, developers can leverage:
- A modular architecture that enables easy switching between different LLMs and voice models. Use state-of-the-art LLMs with large parameter counts where needed. Or use models optimized for conversational response times.
- Multi-turn context management, with tool calling and vision input.
- Voice-to-voice response times as low as 500ms.
- Interruption handling with word-level context accuracy.
- Phrase endpointing that combines voice activity detection, semantic cues, and noise-level averaging.
- Echo cancellation and background noise reduction.
- Metrics and observability down to the level of individual media streams from every session.
Flexibility to use the best models, and the best models for your use case
Daily Bots developers can use both commercial and open models. You can use our integrated LLMs, or "Bring Your Own (API) Key" (BYOK) for your preferred service.
We’ve directly integrated with Anthropic, Cartesia, Deepgram, and Together AI.
- Anthropic’s Claude 3.5 Sonnet is an excellent multi-turn conversational model. Daily Bots includes support for Sonnet’s vision input, tool calling, and the brand new context caching feature.
- Cartesia’s Sonic voice model has raised the bar for voice quality at extremely low latencies. Cartesia offers a wide range of excellent voices, plus the ability to create your own voices.
- Deepgram is a long-time Daily partner and the long-time leader in real-time speech to text accuracy and multi-language support.
- Together AI delivers fast, high quality inference for all three sizes of Meta’s Llama 3.1 LLMs: 8B, 70B, and 405B.
With all of these partners, we do consolidated billing. You get just one bill from Daily, with line items showing your usage of each model. Also, it’s likely that you will benefit from higher rate limits and lower pricing when you use our partners’ services through Daily Bots. See Daily Bots pricing here.
Of course, you can always BYOK for both our partners and other services.
We can support any LLM provider that offers OpenAI-compatible APIs. We work regularly with OpenAI, Groq, and Fireworks, for example.
If you need custom models, our partners offer fine-tuned models and inference services for enterprise customers.
Daily Bots infrastructure can also be deployed inside your Virtual Private Cloud. If you manage your own inference, co-locating orchestration compute with inference has latency, cost, and compliance benefits.
Build now, and for the future
Our goal with Daily Bots is to accelerate the development of real-time, multimodal AI.
With a few lines of code, configure bots that scale on demand, on Daily’s infrastructure, automatically keeping pace as your application’s usage increases.
Write clients for iOS, Android, and the Web using the RTVI Open Source SDKs and Daily Bots helper libraries.
Buy phone numbers from Daily and make your bots accessible via dial-in.
All of this runs on Daily’s Global Mesh Network. Our distributed points of presence deliver 13ms first-hop latency to 5 billion people on six continents. (A little more, on average, if you happen to be in Antarctica.)
It’s also worth noting that Daily Bots is only one of your options, if you’re building real-time AI agents on the Open Source toolkits we use at Daily.
Definitely go check out Vapi and Tavus, for example. They’ve developed specialized technology, and best practices, to support different applications of multimodal inference. Vapi has great voice APIs, with user-friendly dashboards and excellent telephony support. Tavus’s Conversational Video Interface powers AI apps that can speak, hear, and see naturally. We’re proud these innovative platforms also leverage Daily’s WebRTC infrastructure.
If you’re interested in real-time AI, you can leverage Tavus or Vapi; build on the Daily Bots Open Source cloud; or strike out on your own and stand up your own Pipecat-based infrastructure!
Demos, demos, demos & starting out
We’ve had a ton of fun building out Daily Bots.
- Check out Chad’s function-calling weather reporter, and our ExampleBot playground demo. There's also a vision demo, and iOS and Android.
- Get started with a special launch week $10 credit by signing up for Daily Bots here. Or go straight to the docs.
AI is moving fast! Check out Vapi and Tavus. Join the Daily community on Discord. Let us know if you find Daily Bots, RTVI, and Pipecat useful. We’re excited to build the future with you.
]]>
Speed is important for voice AI interfaces. Humans expect fast responses in normal conversation – a response time of 500ms is typical. Pauses longer than 800ms feel unnatural.
Source code for the bot is here. And here is a demo you can interact with.
Technical tl;dr
Today’s best transcription models, LLMs, and text-to-speech engines are very good. But it’s tricky to put these pieces together so that they operate at human conversational latency. The technical drivers that are most important, when optimizing for fast voice-to-voice response times are:
- Network architecture
- AI model performance
- Voice processing logic
Today’s state-of-the-art components for the fastest possible time to first byte are:
- WebRTC for sending audio from the user’s device to the cloud
- Deepgram’s fast transcription (speech-to-text) models
- Llama 3 70B or 8B
- Deepgram’s Aura voice (text-to-speech) model
In our original demo, we self-host all three AI models – transcription, LLM, and voice generation – together in the same Cerebrium container. Self-hosting allows us to do several things to reduce latency.
- Tune the LLM for latency (rather than throughput).
- Avoid the overhead of making network calls out to any external services.
- Precisely configure the timings we use for things like voice activity detection and phrase end-pointing.
- Pipe data between the models efficiently.
We are targeting an 800ms median voice-to-voice response time. This architecture hits that target and in fact can achieve voice-to-voice response times as low as 500ms.
Optimizing for low latency: models, networking, and GPUs
The very low latencies we are targeting here are only possible because we are:
- Using AI models chosen and tuned for low latency, running on fast hardware in the cloud.
- Sending audio over a latency-optimized WebRTC network.
- Colocating components in our cloud infrastructure so that we make as few external network requests as possible.
AI models and latency
All of today’s leading LLMs, transcription models, and voice models generate output faster than humans speak (throughput or tokens per second). So we don’t usually have to worry much about our models having fast enough throughput.
On the other hand, most AI models today have fairly high latency relative to our target voice-to-voice response time of 500ms. When we are evaluating whether a model is fast enough to use for a voice AI use case, the kind of fast we’re measuring and optimizing is the latency kind.
We are using Deepgram for both transcription and voice generation, because in both those categories Deepgram offers the lowest-latency models available today. Additionally, Deepgram’s models support “on premises” operation, meaning that we can run them on hardware we configure and manage. This gives us even more leverage to drive down latency. (More about running models on hardware we manage, below.)
Deepgram’s Nova-2 transcription model can deliver transcript fragments to us as quickly as 100ms. Deepgram’s Aura voice model running in our Cerebrium infrastructure has a time to first byte as low as 80ms. These latency numbers are very good! The state of the art in both transcription and voice generation are rapidly evolving, though. We expect lots of new features, new commercial competitors, and new open source models to ship in 2024 and 2025.
Llama 3 70B is among the most capable LLMs available today. We’re running Llama 3 70B on NVIDIA H100 hardware, using the vLLM inference engine. This configuration can deliver a median time to first token (TTFT) latency of 80ms. The fastest hosted Llama 3 70B services have latencies approximately double that number. (Mostly because there is significant overhead in making a network request to a hosted service.) Typical TTFT latencies from larger-parameter SOTA LLMs are 300-400ms.
WebRTC networking for voice AI
WebRTC is the fastest, most reliable way to send audio and video over the Internet. WebRTC connections prioritize low latency and the ability to adapt quickly to changing network conditions (for example, packet loss spikes). For more information about the WebRTC protocol and how WebRTC and WebSockets complement each other, read this short explainer.
Connecting users to nearby servers is also important. Sending a data packet round-trip between San Francisco and New York takes about 70ms. Sending that same packet from San Francisco to, say, San Jose takes less than 10ms.
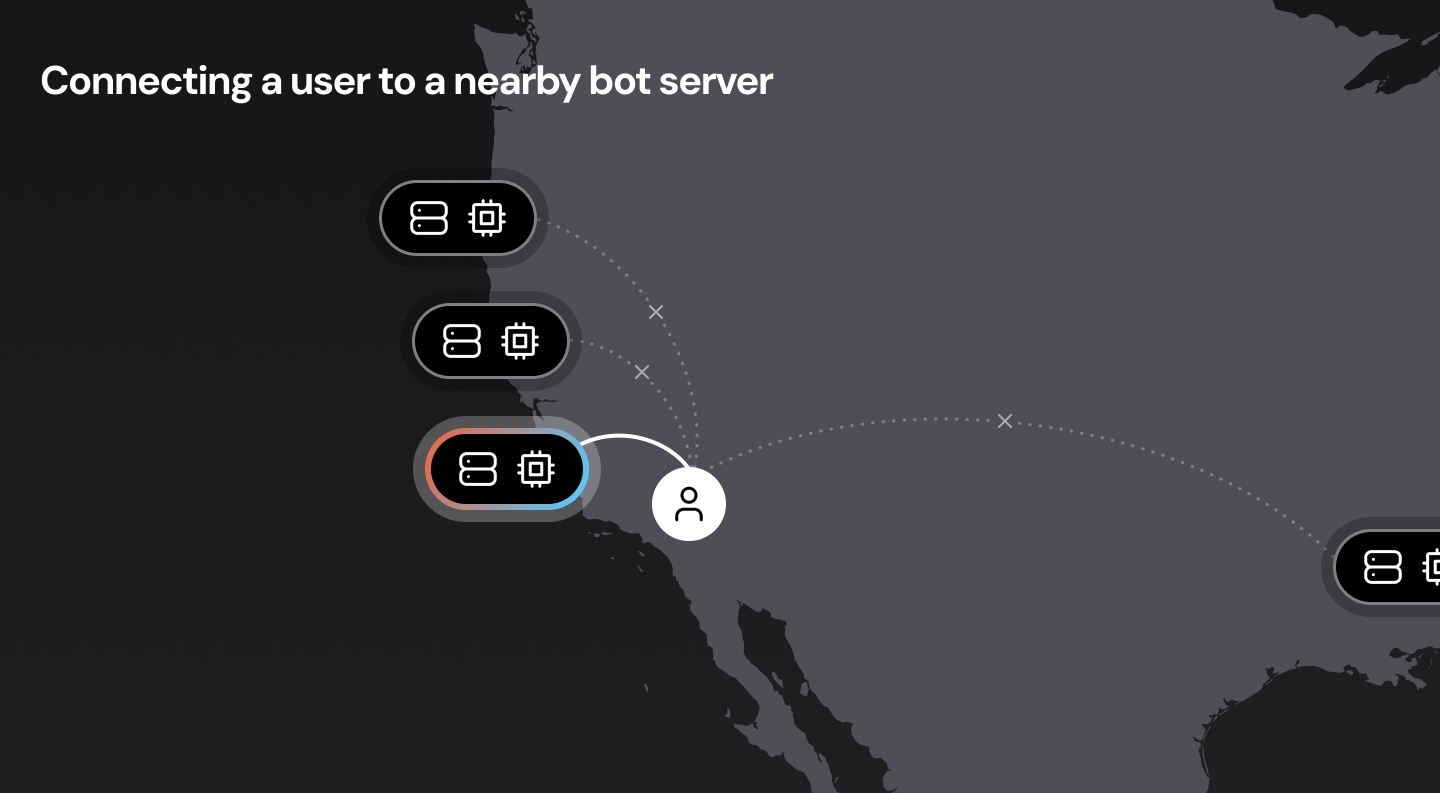
In a perfect world, we would have voice bots running everywhere, close to all users. This may not be possible, though, for a variety of reasons. The next best option is to design our network infrastructure so that the “first hop” from the user to the WebRTC cloud is as short as possible. (Routing data packets over long-haul Internet connections is significantly slower and more variable than routing data packets internally over private cloud backbone connections.) This is called edge or mesh networking, and is important for delivering reliable audio at low latency to real-world users. If you’re interested in this topic, here’s a deep dive into WebRTC mesh networking.
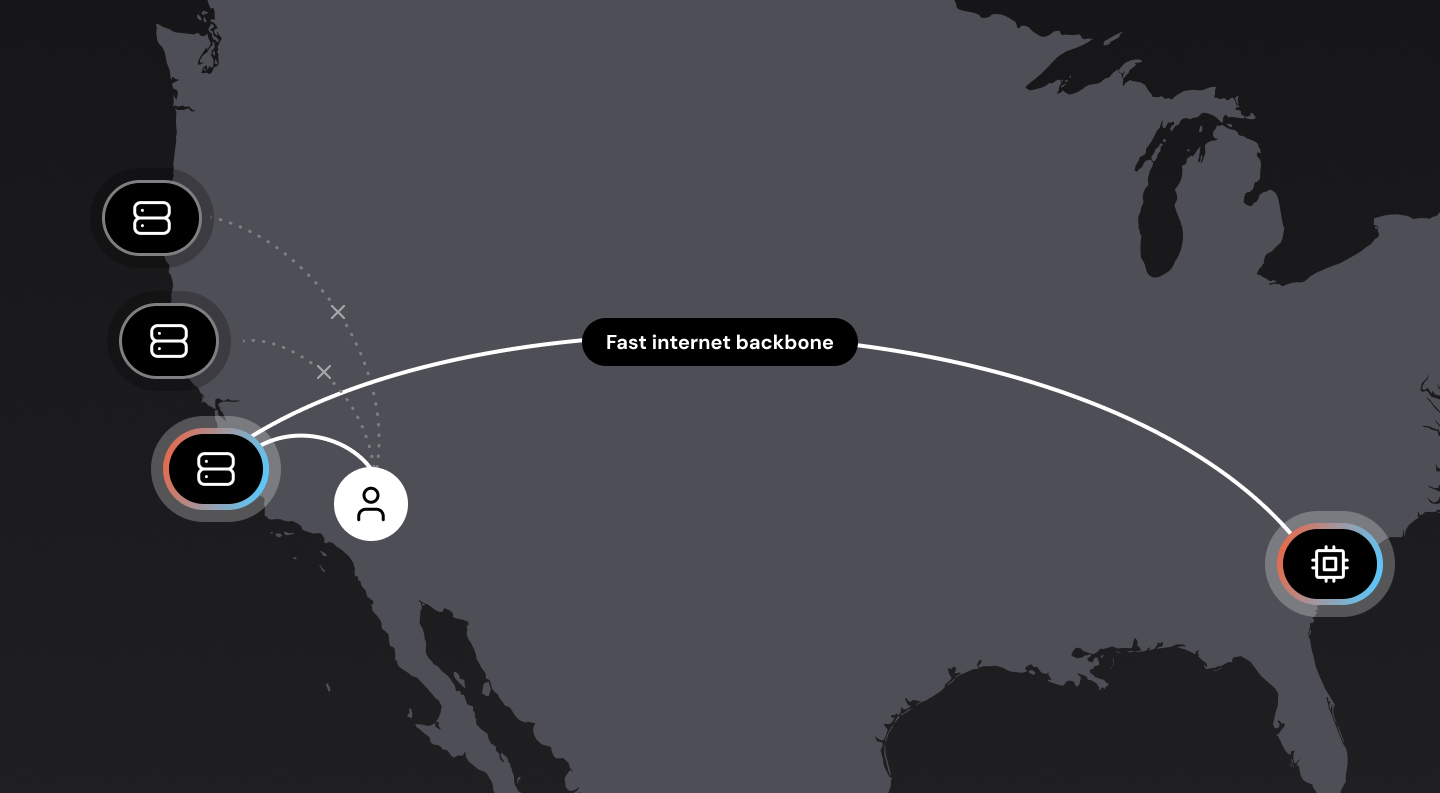
Where the components run – self-hosting the LLM and voice models
The code for an AI voice bot is usually not terribly large or complicated. The bot code manages the orchestration of transcription, LLM context-management and inference, and text-to-speech voice generation. (In many applications, the bot code will also read and write data from external systems.)
But, while voice bot logic is often simple enough to run locally on a user’s mobile device or in a web browser process, it almost always makes sense to run voice bot code in the cloud.
- High-quality, low-latency transcription requires cloud computing horsepower.
- Making multiple requests to AI services – transcription, LLM, text-to-speech – is faster and more reliable from a server in the cloud than from a user’s local machine.
- If you are using external AI services you need to proxy them or access them only from the cloud to avoid baking API keys into client applications.
- Bots may need to perform long-running processes, or may need to be accessible via telephone as well as browser/app.
Once you are running your bot code in the cloud, the next step in reducing latency is to make as few requests out to external AI services as possible. We can do this by running the transcription, LLM, and text-to-speech (TTS) models ourselves, on the same computing infrastructure where we run the voice bot code.
Colocating voice bot code, the LLM, and TTS in the same infrastructure saves us 50-200ms of latency from network requests to external AI services. Managing the LLM and TTS models ourselves also allows us to tune and configure them to squeeze out even more latency gains.
The downside of managing our own AI infrastructure is additional cost and complexity. AI models require GPU compute. Managing GPUs is a specific devops skill set, and cloud GPU availability is more constrained than general compute (CPU) availability.
Voice AI latency summary – adding up all the milliseconds
So, if we’re aiming for 800ms median voice-to-voice latency (or better) what are the line items in our latency “budget?”
Here’s a list of the processing steps in the voice-response loop. These are the operations that have to be performed each time a human talks and a voice bot responds. The numbers in this table are typical metrics from our reasonably well optimized demo running on NVIDIA containers hosted by Cerebrium.

Next steps
For some voice agent applications, the cost and complexity of managing AI infrastructure won’t be worth taking on. It’s relatively easy today to achieve voice-to-voice latency in the neighborhood of two to four seconds using hosted AI services. If latency is not a priority, there are many LLMs that can be accessed via APIs and have time to first token metrics of 500-1500ms. Similarly, there are several good options for transcription and voice generation that are not as fast as Deepgram, but deliver very high quality text-to-speech and speech-to-text.
However, if fast, conversational voice responsiveness is a primary goal, the best way to achieve that with today’s technology is to optimize and colocate the major voice AI components together.
If this is interesting to you, definitely try out the demo, read the demo source code (and experiment with the Pipecat open source voice AI framework), and learn more about Cerebrium's fast and scalable AI infrastructure.
]]>Unlock enhanced video quality and performance with Daily Adaptive Bitrate, combining ultra-reliable calls and the best visual experience your network can offer—automatically adjusting in real-time to suit fluctuating network conditions.
Since its launch, Daily has been at the forefront of providing the most advanced simulcast APIs of any WebRTC provider. Developers who choose Daily benefit from complete flexibility and control, enabling them to optimize the performance of their video applications across various devices and network conditions. This level of customization allows developers to fine-tune the user experience to match their specific goals.
Simulcast is an invaluable feature for video applications, enabling developers to balance between quality and reliability. It can, however, be challenging to implement when seeking the perfect middle ground for all connected peers in real-world, changing network conditions. Adjusting simulcast settings in real-time to maintain performance requires on-going peer network monitoring, client-side logic, and can be tricky to debug.
Imagine a scenario where developers no longer need to worry about optimizing for quality, and can instead have full confidence that video will automatically look its best within the available bandwidth. This would greatly simplify development, allowing engineers to focus on other aspects of their application.
Daily Adaptive Bitrate (ABR)
Daily Adaptive Bitrate is an industry-first innovation that automatically adjusts the quality of video to ensure maximum performance without compromising reliability.
When network is constrained, the bitrate and resolution will be dropped to ensure that the call remains connected (ensuring enough throughput for audio.) When there’s bandwidth headroom, the bitrate and resolution will be increased to deliver higher quality video.
It doesn’t require any pre-configured video settings, or client side network monitoring and adjustment.
- In 1:1 calls, only a single dynamic layer of video is sent, saving bandwidth and allowing for higher overall video quality.
- In multi-party calls, the top layer is always adaptive based on network conditions and lower layers are used for smaller UI elements (such as sidebars or large grids) or as a fallback for poor network conditions.
Let’s take a look at an example...
Here are some typical simulcast settings that are somewhat conservative to optimize for reliability:
- High layer:
{ maxBitrate: 700 kbps, targetResolution: 640x360, maxFramerate: 30 fps } - Medium layer:
{ maxBitrate: 200 kbps, targetResolution: 427x240, maxFramerate: 15 fps } - Low layer:
{ maxBitrate: 100 kbps, targetResolution: 320x180, maxFramerate: 15 fps }
A user joins a 1:1 call from a WiFi network with speeds of 5 Mbps down, 1 Mbps up. Upon joining the call, due to the network’s slow upload speed, the user is unable to send all three layers. The available options are to either: a) drop the framerate, or b) drop the highest layer.
As a result, this user will:
- ⬇️ Send - 360p video @ 15 fps, or 240p video @ 15 fps
- ⬆️ Receive - 360p video @ 30 fps
With Daily Adaptive Bitrate enabled, Daily will automatically optimize the experience based on available bandwidth. Given the 5 Mbps down / 1 Mbps up network, the user will:
- ⬇️ Send - 540p video @ 30 fps (around 800 kbps)
- ⬆️ Receive - 720p video @ 30 fps (around 2 Mbps)
Compared to a hardcoded simulcast configuration, this is a dramatic increase in call quality for the user that doesn't sacrifice call reliability.
Getting started
Daily Adaptive Bitrate has been rigorously tested at scale for some time now. It is enabled by default for all 1:1 calls, or can be manually configured by following these steps:
- Set the
enable_adaptive_simulcastproperty totruefor either your domain (e.g. all calls) or room (e.g. specific calls). - If you’re a Prebuilt user, no additional configuration is needed.
- If you’ve built a custom app with daily-js, please update to version
0.60.0or0.61.0for daily-react-native. - The only code change required is to set the
allowAdaptiveLayerswithin thesendSettingsproperty totrueat join time:
const call = Daily.createCallObject();
call.join({
sendSettings: {
video: {
allowAdaptiveLayers: true
}
}
});Please note that Daily Adaptive Bitrate currently works best on Chrome and Safari (both desktop and mobile). Firefox support will ship mid-year, although users on Firefox can still join the call unimpeded sending video using 3-layer simulcast.
Multi-party (>2 participants) are currently in beta – please contact us if you'd like to take part in testing.
For more information regarding Daily Adaptive Bitrate, please refer to our documentation here. We’re excited to see how this feature improves both the developer and end-user experience on the Daily platform. As always, for any questions or feedback, feel free to reach out.
]]>I’ve talked before on this blog about the surprising complexities of recording WebRTC calls. Today I’d like to discuss the case of web page recording more widely.
The solutions explained here also have relevance to web application UI architecture in general. I’m going to show you some ideas for layered designs that enable content-specific acceleration paths. This is something web developers typically don’t need to think about very often, but it can be crucial to unlocking high performance. Examining the case of web page recording can help to understand why.
Daily’s video rendering engine VCS is designed for this kind of layered architecture, so you can apply these ideas directly on Daily’s platform. At the end of this post, I’ll talk more about VCS specifically and how web page recording fits into the picture.
Three types of web capture
First we should define more precisely what’s meant by “recording”. We’re talking about using a web browser application running on a server in a so-called headless configuration (i.e., no display or input devices are connected).
With such a setup, there are several ways to capture content from a web page:
- Extracting text and images, and perhaps downloading embedded files like video. This is usually called scraping. The idea is to capture only the content that is of particular interest to you, rather than a full snapshot of a web application’s execution. Crawling, as done by search engines, is an adjacent technique (traditionally crawlers didn’t execute JavaScript or produce an actual browser DOM tree, but today a lot of content is in web applications that can’t be parsed without).
- Taking screenshots of the browser at regular intervals or after specific events. This is usually in the context of UI testing, and more generally, falls under the umbrella of browser automation. You might use the produced screenshots to compare them with an expected state (i.e., a test fails if the browser’s output doesn’t match). Or the screenshots could be consumed by a “robot” that recognizes text content, infers where UI elements are located, and triggers events to use the application remotely.
- Capturing a full A/V stream of everything the browser application outputs, both video and audio, and encoding it into a video file. This is effectively a remote screen capture on a server computer that doesn’t have a display connected.
In this post, I’ll focus on the last kind of headless web page recording: capturing the full A/V stream from the browser. Because we’re capturing the full state of the browser’s A/V output, it is much more performance-intensive than the more commonplace scraping or browser automation.
Those use cases can get away with capturing images only when needed. But for the A/V stream, the browser’s rendering needs to be captured at a stable 30 frames per second. Everything that can happen within the web page needs to be included: CSS animations and effects, WebRTC, WebGL, WebGPU, WebAudio, and so on. With the more common browser automation scenario, you have the luxury of disabling browser features that don’t affect the visual state snapshots you care about. But this is not an option for remote screen capture.
So why would you even want this? Clearly it’s more of a niche case compared to scraping and browser automation, which are massively deployed and well understood. The typical scenario for full A/V capture is that you have a web application with rich content like video and dynamic graphics, and you want to make a recording of everything that happens in the app without requiring a user to activate screen capture themselves. When you’ve already developed the web UI, it seems like the easy solution would be to just capture a screen remotely. Surely that’s a solved problem because the browser is so ubiquitous…?
Unfortunately it’s not quite that simple. But before we look at the details, let’s do a small dissection of an example app.
What to record in a web app
The following UI wireframe shows a hypothetical web-based video meeting app, presumably implemented on WebRTC:
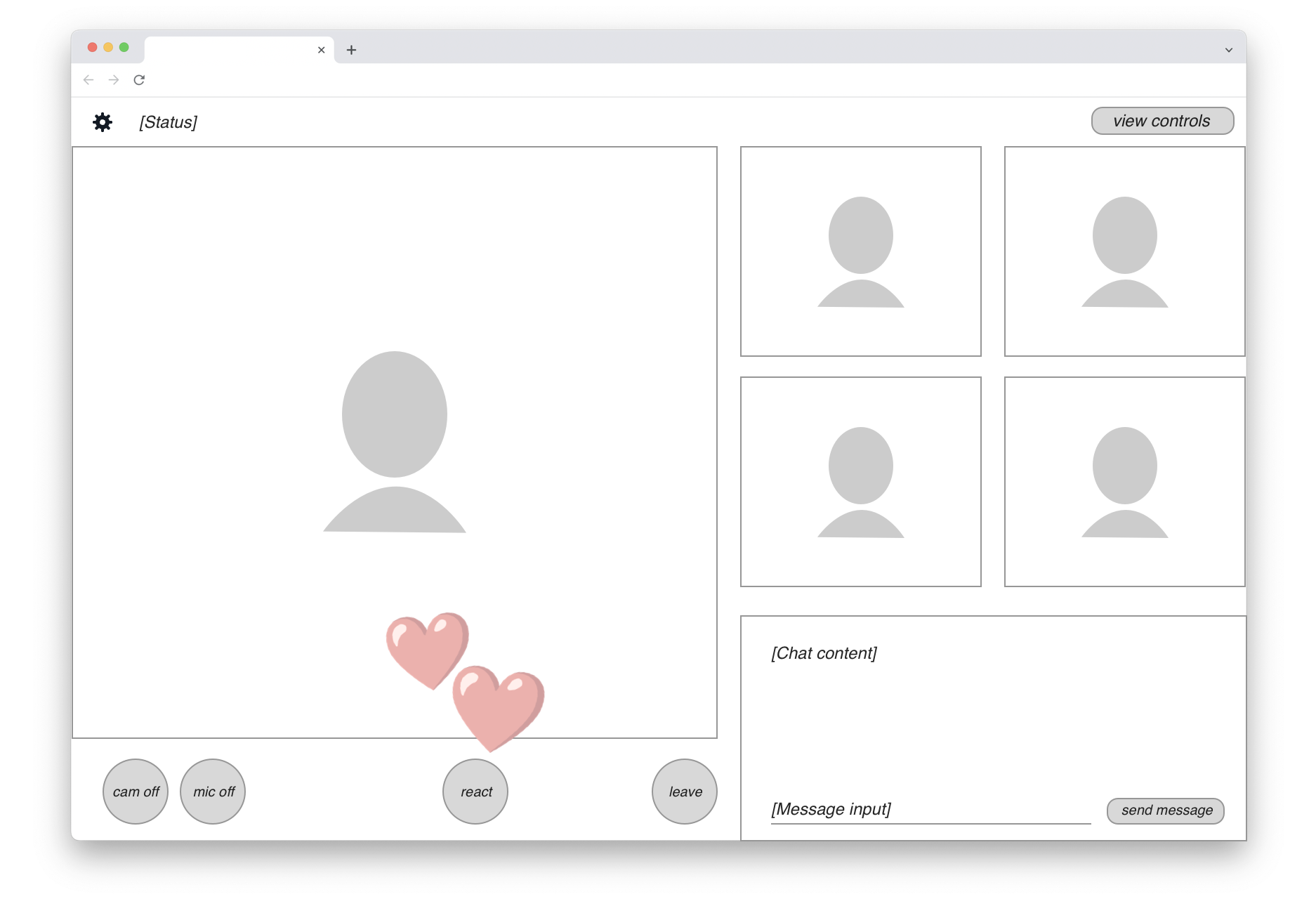
There are up to five participant video streams displayed. In the bottom-right corner, a live chat view is available to all users. In the bottom-left row, we find standard video call controls and a “React” button that lets users send emojis. When that happens, an animated graphic is rendered on top of the video feed (shown here by the two floating hearts).
Recording a meeting like this means you probably want a neutral viewpoint. In other words, the content shown in the final recording should be that of a passive participant who doesn’t have any of the UI controls.
The content actually needed for the headless recording is marked with a blue highlight in this drawing:
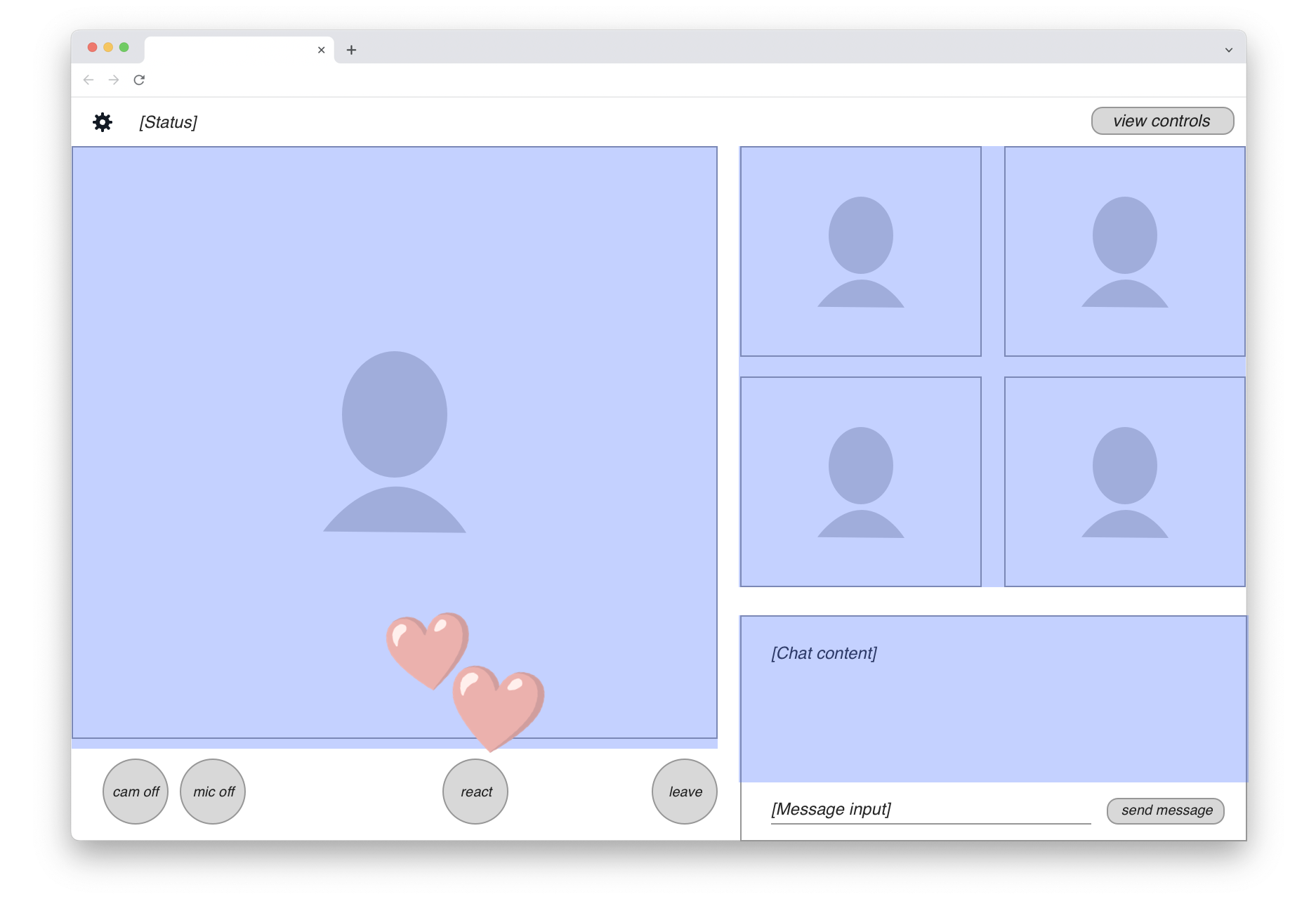
We can see that the majority of UI elements on the page should actually be excluded from the recording. So in fact, the “web page recording” we seek isn’t quite as straightforward as just running a screen capture. We’ll clearly need to do some front-end engineering work to create a customized view of the application for the recording target.
Assuming this development work is done, where can we then run these remote screen capture jobs? Here is the real rub.
Competing for the hottest commodity in tech
The web browser offers a very rich palette of visual capabilities to application developers. CSS includes animations, transitions, 3D layer transformations, blending modes, effects like Gaussian blur, and more — all of which can be applied together. On top of that we’ve got high-performance rendering APIs like Canvas, WebGL and today also WebGPU. If you want to capture real web apps at 30 fps, you can’t easily pick a narrow subset of the capabilities to record. It’s all or nothing.
Intuitively the browser feels like a commodity application because it runs well on commodity clients like cheap smartphones, low-end laptops, and other devices. But this is achieved by extensive optimization for the modern client platform. The browser relies on client device GPUs for all of its visual power. A mid-range smartphone that can run Chromium with the expected CSS bells and whistles has an ARM CPU and an integrated GPU, both fully available to the browser application.
Commodity servers are a very different hardware proposition. An ordinary server has a fairly high-end Intel/AMD CPU, but it’s typically virtualized and shared by many isolated programs running on the same hardware. Crucially, there is no GPU on this commodity server. This means that all of Chromium’s client-oriented rendering optimizations are unavailable.
It’s possible to get a server with a GPU, but these computers are nothing like the simple smartphone or laptop for which Chromium is optimized. GPU servers are designed for the massive number crunching required by machine learning and AI applications. These special GPUs can cost tens of thousands of dollars and they include large amounts of expensive VRAM. All this special hardware goes largely unused if you use such a GPU to render CSS effects and some video layers that a Chromebook could handle.
At the moment of this writing, the situation is even worse because these GPU servers happen to be the hottest commodity in the entire tech industry. Everybody wants to do AI. The demand is so massive that Nvidia, the main provider of these chips, has taken an active role in picking which customers actually get access. This was reported by The Information:
Nvidia plays favorites with its newest, much-sought-after chips for artificial intelligence, steering them to small cloud providers who compete with the likes of Amazon Web Services and Google. Now Nvidia is also asking some of those small cloud providers for the names of their customers—and getting them—according to two people with direct knowledge.
It's reasonable that Nvidia would want to know who’s using its chips. But the unusual move also could allow it to play favorites among AI startups to further its own business. It’s the latest sign that the chipmaker is asserting its dominance as the major supplier of graphics processing units, which are crucial for AI but in short supply.
In this situation, using server GPUs for web page recording would be like taking a private jet to go to work every morning. It’s technically possible, but you’d need an awfully good reason and some deep pockets.
There are ways to increase efficiency by packing multiple browser capture jobs on one GPU server. But you’d still be wasting most of the expensive hardware’s capabilities. Nvidia’s AI/ML GPUs are designed for high-VRAM computing jobs, not the browser’s GUI-oriented graphics tasks where memory access is relatively minimal.
Let’s think back to the private jet analogy. If you have a jet engine but your commute is only five city blocks, it doesn’t really help at all if you ask all your neighbors to join you on the plane trip — it’s still the wrong vehicle to get you to work. Similarly, with the server GPUs, there’s a fundamental mismatch between your needs and the hardware spec.
Why generic hardware needs specialized software
Is there a way we could render the web browser’s output on those commodity CPU-only servers instead? The problem here lies in the generic nature of the browser platform combined with the implicit assumptions of the commodity client hardware.
I noted above that capturing a web app ends up being “all or nothing” — a narrow subset of CSS is as good as useless. A browser automation system has more freedom here. It can execute on the CPU because it has great latitude for trade-offs across several dimensions of time and performance:
- When to take its screenshots
- How much rendering latency it tolerates
- Which expensive browser features to disable
In other words, browser automation can afford wait states and it can skip animations, but remote screen capture can’t. It must be real-time.
Fundamentally we have here a performance sinkhole created from combining two excessively generic systems. Server CPUs are a generic computing solution, not optimized for any particular application. The web browser is the most generic application platform available. Multiplying compromise by another compromise is like multiplying small fractions — the product is less than the individual components. Without any specialized acceleration on either the hardware or software side, we’re left in a situation where 30 frames per second on arbitrary user content remains an elusive dream.
Maybe we just use more CPU cores in the cloud? That’s a common solution, but it quickly becomes expensive, and it’s still susceptible to web content changes that kill performance.
For example, you can turn any DOM element within a web page into a 3D plane by adding perspective and rotateX CSS transform functions to it. Now your rendering pipeline suddenly has to figure out questions like texture sampling and edge antialiasing for this one layer. Even with many CPU cores, this will be a massive performance hit. And if you try to prevent web developers from using this feature, there’s always the next one. It becomes an endless whack-a-mole of CSS properties which will frustrate developers using your platform as the list of restrictions grows with everything they try.
Given that we can’t provide acceleration on the hardware side (those elusive server GPUs…), the other option left is to accelerate the software.
Designing for layered acceleration
At this point, let’s take another look at the hypothetical web app whose output we wanted to capture up above.
Within the UI area to be recorded, we can identify three different types of content. They are shown here in blue, pink, and green highlights:
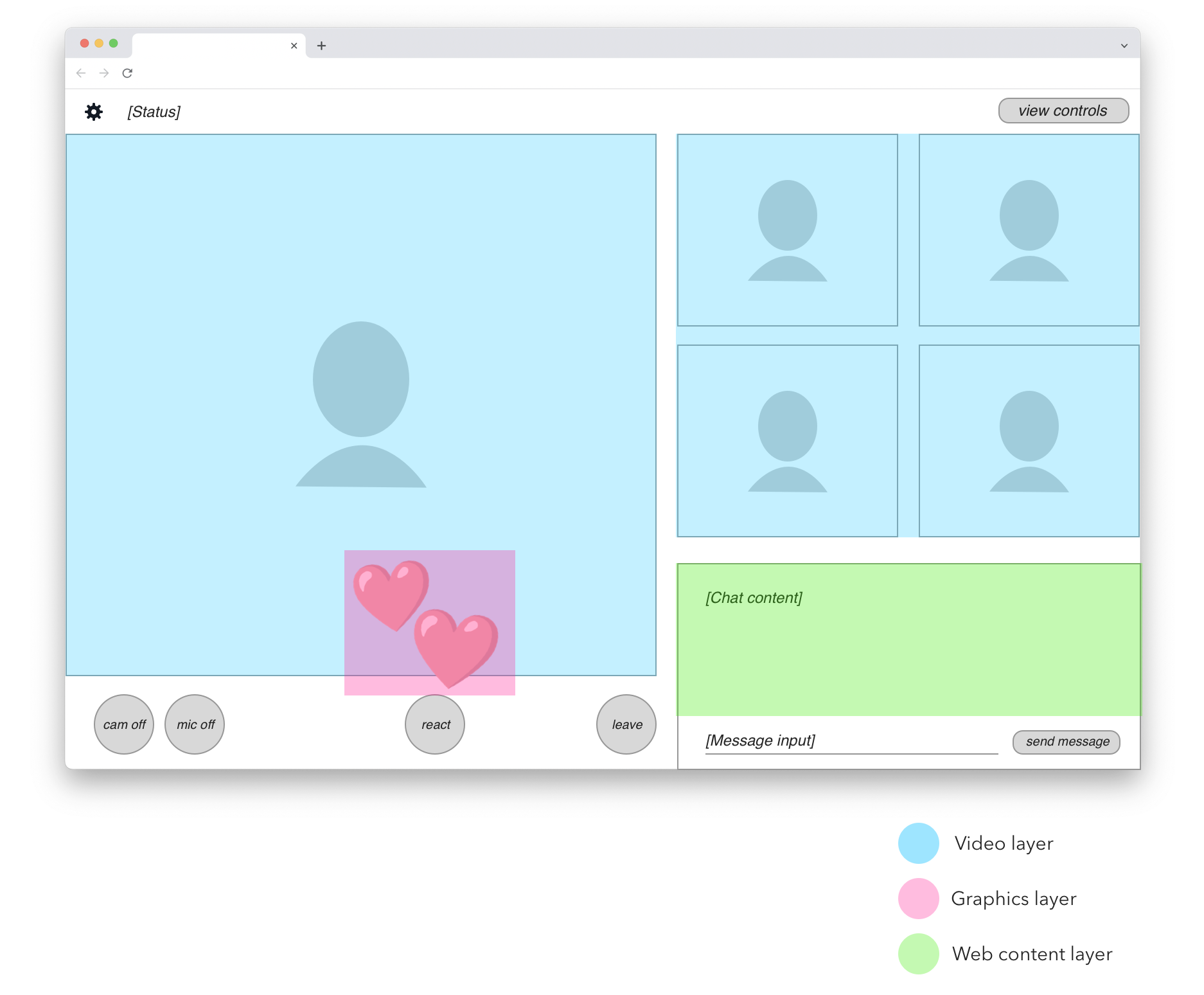
In blue we have participant videos. These are real-time video feeds decoded from data received over WebRTC.
In pink we have animated overlay graphics. In this simplified example, it’s only the emoji heart reactions. In a real application we would probably identify other graphical elements, such as labels or icons that are rendered on top of participant videos.
In green we have the shared chat view. This is a good example of web content that doesn’t require full 30 fps screen capture to be rendered satisfactorily. The chat view only updates every second at most, is not real-time latency sensitive, and doesn’t depend on CSS animations, video playback, or fancy WebGL. We can render this content on a much more limited browser engine than what’s required for complete web page recording.
Identifying these layers is key to unlocking the software-side acceleration I mentioned earlier. If we could split each of these three content types onto separate rendering paths and put them together at the last moment, we could optimize the three paths separately for reasonable performance on commodity servers.
The accelerated engine
Could we do this by modifying the web browser itself? Forking Chromium would be a massive development effort and we’d be scrambling to keep up with updates. But more fundamentally, technologies like CSS are simply too good at enabling developers to make tiny code changes that will completely break any acceleration path we can devise.
At Daily, we provide a solution in the form of VCS, the Video Component System. It’s a “front-end adjacent” platform that adopts techniques of modern web development, but is explicitly designed for this kind of layered acceleration.
With VCS, you can create React-based applications using a set of built-in components that always fall on the right acceleration path. For example, video layers in VCS are guaranteed to be composited together in their original video-specific color space, unlocking higher quality and guaranteed performance. There's no way a developer can accidentally introduce an unwanted color space conversion.
For content like the green-highlighted chat box in the previous illustration, VCS includes a WebFrame component that lets you embed arbitrary web pages inside the composition, very much like an HTML <iframe>. It can be scaled individually and remote-controlled with keyboard events. This way you can reuse dynamic parts of your existing web app within a VCS composition without wrecking the acceleration benefits for video and graphics.
VCS is available on Daily’s cloud for server-side rendering of recordings and live streams. With the acceleration-centric design, we can offer VCS as an integral part of our infrastructure, available for any and all recordings. It’s not a separately siloed service with complex pricing. That means you always save money, and we can guarantee that it will scale even if your needs grow quickly.
This post has more technical detail on how you might implement a layered web page recording on VCS. Look under the heading “Live WebFrame backgrounds”.
One more thing to consider… The benefits of layered acceleration can be more widely useful than just for servers. If you can structure your application UI this way, why not run the same code on clients too? For that purpose, we offer a VCS web renderer that can be embedded into any web app regardless of what framework you’re using. This lets you isolate performance-intensive video rendering into a managed “acceleration box” and focus on building the truly client-specific UI parts that are not shared with server-side rendering.
For a practical example of how to use the VCS web renderer, see the Daily Studio sample application. It’s a complete solution for Interactive Live Streaming where the same content can be rendered on clients or servers as needed.
Summary
In this post, we discussed the challenges and solutions to web page recording. Hardware acceleration is an expensive commodity, so Daily provides an alternative, more cost-effective solution in the form of our Video Component System which can include layered web content.
If you have any questions about VCS, don't hesitate to reach out to our support team or head over to our WebRTC community.
]]>Twilio recently announced that the Twilio Video WebRTC service will be turned off in December 2024.
On January 22 we hosted a live webinar for Twilio Video customers who are beginning the process of porting their products over to other video platforms.
Daily is a seamless migration option for Twilio Video customers. We provide all of the features of Twilio Video plus many more, have a long history of operating our industry’s most innovative WebRTC developer platform, and offer dedicated engineering resources to customers porting from Twilio. For more information about Daily, please visit our Twilio Migration Resources hub.
Below, we’ve embedded a video of the webinar, including the Q&A section. Underneath the video is a transcript.
Introduction to Twilio Video Migration webinar
Hi. Welcome to this conversation about porting telehealth applications from Twilio Video to other video platforms.
If you're here, it's likely you were impacted by the announcement in December that Twilio is leaving the video developer tools space.
Twilio is giving customers a year to transition.
We know how disruptive it is to have to change platforms. My hope is that our notes today will make things a little bit easier. At Daily, we've seen what approaches work well when porting between video platforms, and what approaches create risks.
Today, we'll:
- cover high-level best practices
- talk through the major choices you'll need to make, and
- try to give you a sense of timelines and resource requirements
If your engineering team knows your product codebase well and understands your Twilio Video implementation, you will be able to transition to a new platform without too much difficulty. If you need engineering support, the new platform vendor you are moving to should be able to help you, and there are excellent independent dev shops that specialize in video implementation.

So, let's talk about the big tasks involved in porting your code. Here's how we break down a project:
Major components of a porting project
- choosing a new platform
- planning and allocating resources
- writing the code and testing it
- moving traffic
Choosing a platform

Build or buy
Twilio Video is a fully managed service. What our industry calls a PaaS, or Platform-as-a-Service.
When you migrate off of Twilio Video, you could migrate to another managed platform, or you could stand up, and manage, your own video infrastructure.
This is a classic software engineering build vs buy decision. I'm not going to spend too much time on this today, because the majority of the Twilio Video customers that we've talked to plan to stay in the managed platform world.

But we do often get asked about build vs buy in our space, so I'll cover this briefly, and at a high live. I really like talking about video tech, so if you want to dive deeper on this topic, come find me on Twitter or LinkedIn.

Here are the three most important things to consider when thinking through a build vs buy decision. We've found this is sometimes new information for engineering teams thinking about standing up their own video infrastructure.
First, managed services operate at significant economies of scale, so it's very hard to save money compared to paying someone else to run your video infrastructure. The rough rule of thumb is that you'll need to be paying a video platform about $3m/year before you can approach the break-even cost of paying for your own infrastructure directly.
Second, there are no off-the-shelf devops, autoscaling, observability, or multi-region components available for real-time video infrastructure. There are good open source WebRTC media servers, but they are building blocks for operating in production at scale, not complete solutions for operating in production at scale. It's easy to deploy an open source WebRTC server for testing. But for production, you'll need to build out quite a lot of custom devops tooling.
Third, real-time video infrastructure is a specific kind of high throughput content delivery network. Putting media servers in every geographic region where you have users turns out to be critical to making sure video calls work well on every kind of real-world network connection. You really want servers close to the edge of the network in the terms that our industry uses.
All of the major video platforms — Vonage, Chime, Zoom, Agora, Daily — have servers in two dozen or more data centers. And, today, the platforms that benchmark the best for video quality — Zoom, Agora, and Daily — have built out sophisticated "mesh network" infrastructure that routes video and audio packets from the edge of the network across fast internal backbones.
For all these reasons, I think a managed service is the right choice in almost all cases. I'm biased, of course, because Daily is a managed service. But I've walked through the numbers and the technical requirements here with dozens of customers of different shapes and sizes.
The big five: key factors in platform evaluation
So let's assume today that you are migrating from Twilio Video to another managed platform.
How do you choose which one?

Our recommended approach is to divide your platform evaluation into five topics.
- Reliability
- Quality
- Features and requirements
- Compliance
- Support
Reliability

There are two aspects of reliability: first, overall service uptime. Second, whether video sessions reliably connect and remain connected for any user, anywhere in the world, on any network.
The importance of uptime is obvious.
I won't say much more about this, other than that every vendor should have a status page and good due diligence here is to look back through all listed production incidents on the status page to get a sense of how your vendor approaches running infrastructure at scale.
Every large-scale production system has incidents. The goal for those of us who run these systems is to minimize both overall issues and the impact of any one issue. Everything should be -— as much as possible — redundant, heavily monitored, and over-provisioned.
In general, I think that system reliability is not a distinguishing factor for the major providers in our space. Those of us who have been running real-time video systems at scale for 6, 8, 10 years all have a track record of reliability and uptime.
If you're considering a newer vendor, though, it's definitely worth doing extra diligence about uptime.
The other aspect of reliability is a distinguishing factor between vendors. This is the connection success rate – will your users video sessions connect and stay connected, on any given day, for all of your users?

The big things to ask about here are:
- Does a vendor have infrastructure in every region where you have users? If not, many of those users will have to route via long-haul, public internet routes, and some of those calls will fail.
- Does a vendor heavily test and benchmark on a wide variety of real-world networks?
- Does a vendor heavily test and optimize on a wide variety of real-world devices, including older devices and mobile Safari? Device support is, surprisingly, not something that every video vendor prioritizes.
Quality
That last set of questions is a good transition to talking about video and audio quality.
Video and audio quality are about adapting to a wide range of real-world network conditions.

Delivering the best possible video and audio quality to every user, on every device, everywhere in the world is the second most important job your video vendor should be doing, second only to uptime.
Video and audio quality are critical because bad video experiences lead directly to user churn.

It turns out that platforms have made different amounts of investment in network adaptation, CPU adaptation, and infrastructure over the past five years. Video quality is an area where platform performance does differ.

It's worth understanding what each platform's focus and level of investment in infrastructure and SDK optimizations is. AWS Chime, for example, focuses on the customer support call center use case, and is not very good at adaptive video delivery to the full range of real-world networks and devices. Vonage has not invested in building out infrastructure at the edge of the cloud. Zoom and Agora both focus on native applications and don't fully support web browsers.
Telehealth video and audio quality: real-world conditions
It turns out that video and audio quality for telehealth use cases are challenging in three ways.

Many patients will be on cellular data networks. Many patients will be using mobile devices as opposed to laptop computers. And because installing software introduces significant friction for most users, many telehealth applications are built to run inside web browsers.
A platform vendor should be able to show you benchmarks that tell you how their platform performs on, for example, a poor cellular data or wifi network.
The goal should be to send good quality video whenever possible, and to gracefully degrade the video quality whenever there are network issues, while maintaining audio quality.
Benchmarking video quality
Here's a benchmark that shows video quality adapting to constrained network conditions. We do a lot of benchmarking at Daily. We benchmark our own performance intensively. And we benchmark against our competitors. Our benchmarks are transparent and replicable – we make our benchmarking code available because we think benchmarking is so important.

If you want to do your own independent testing, you can use our benchmarking code. Or you can work with an independent testing partner like testRTC or TestDevLab.
We'll come back to the topic of testing a little bit later.
Now let's talk about a close cousin to testing: observability.
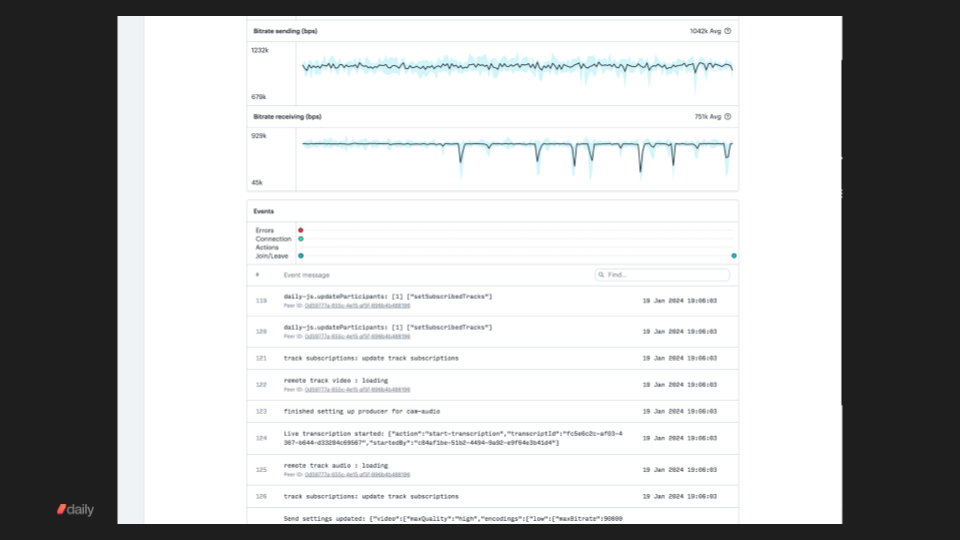
Part of delivering a reliable, best-possible-quality experience to users on any network, any device, anywhere in the world is having actionable metrics and monitoring for every session.
Observability and metrics

Good metrics and monitoring tools are important for two reasons. First, if you're not measuring quality and reliability, it's very hard to make improvements.
Second, you will want to provide customer support to users on an individual basis. So your support team needs tools that allow them to help users debug video issues.
A video platform should give developers and product teams at least three things:
- easy-to-use dashboards
- REST API access to all metrics and SDK action logs
- enterprise tooling integrations

Here's how we check these three boxes at Daily.
Everyone on your team can use our standard dashboard, which gives you point-and-click access to logs and basic metrics from every session.
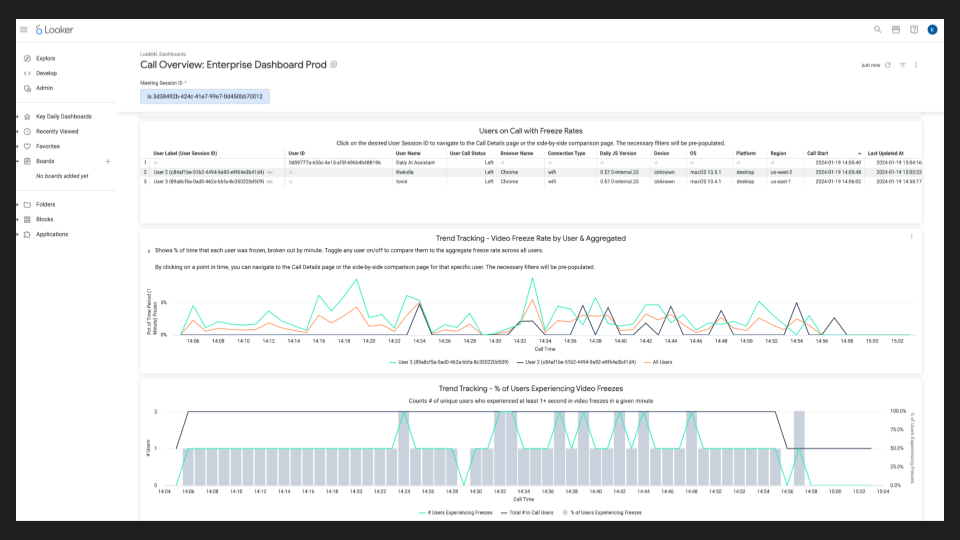
For customers with larger support and data science teams, our enterprise plans come with access to more complex dashboards built in the industry standard Looker BI tool. These Looker dashboards have more views, more aggregates, and are customizable for your team.
And all of the data that feeds our dashboards is available via our REST APIs.
Features and requirements
Features are important! So let's talk about how to do a feature comparison between vendors.

Every vendor will give you a feature checklist. If you're porting an existing application from Twilio Video, our recommendation is to – at least initially – narrow the focus to what you're using today.
I have to note that this advice cuts against one of our strengths at Daily — we have the biggest feature set of any video platform!
But here's why we recommend focusing first on the features you use today, rather than on your roadmap. We've seen over and over that customers will have an ambitious roadmap and will want to see every feature on that roadmap supported by a platform. Which is totally understandable.
However, roadmaps and requirements change over time. And a good platform, a platform that is under active development, will add new features every quarter.
So I think it makes sense to approach a features comparison exercise in two steps.

First, prioritize evaluating how difficult your port from Twilio Video will be. Are there any features missing that will require writing workarounds or changing your product? Because workarounds and product changes introduce real costs and risks.
Second, look at a vendor's history of adding new features. Talk to that vendor. Tell them your roadmap and try to get a sense of whether your roadmap aligns with the platform's roadmaps and commercial goals.
The reality is that Twilio Video's feature set is not very large. It's unlikely that you will have trouble porting a Twilio Video application to another established platform because of any missing features.
Zoom Web SDK: missing features
Ironically, the only established vendor that this is not true of is Zoom. Twilio recommended Zoom as a new home for Twilio's video customers. But Zoom's developer tools are much less mature than their consumer product, and in particular, Zoom's web browser SDK is missing many features.

Everyone in the video space respects Zoom's core technology and infrastructure. But almost everyone was surprised by the partnership with Zoom. Twilio has a history of being a developer-focused company. In this case, however, Zoom paid Twilio to recommend a solution that is not the right fit for most of Twilio's developer customers.
Compliance
Compliance is just as important as reliability, call quality, and features. But we've left it until next-to-last in the evaluation sequence, simply because in the video space all the established vendors are HIPAA-compliant, operate in ISO 27001 certified data centers, and offer data geo-fencing.

I think there are just two nuances to note here.

First, generally speaking, healthcare applications in the US can't use Agora. Agora is a strong player in the video space, but most enterprise compliance departments won't sign off on Agora handling healthcare video and audio traffic.
Agora's headquarters, executives, and engineering team are physically located in China. This means that the Chinese Government has access to all data that Agora handles, and even though Agora has self-certified as HIPAA compliant, Chinese laws about data privacy are generally considered to be incompatible with HIPAA.
The second nuance is that some applications have a hard requirement for true end-to-end encryption. Today, the only way to do true, auditable end-to-end encryption with WebRTC in a web browser is by using peer-to-peer calls. Peer-to-peer calls come with a number of quality disadvantages and feature limitations. For example, no recording or cloud transcription is possible in peer-to-peer calls.
In general, all established WebRTC vendors take data privacy seriously and use strong encryption for every leg of media transport. So a hard requirement for true end-to-end encryption is pretty unusual. But if your application does have this requirement, you'll need to talk to your vendor to make sure they support peer-to-peer calls.
Engineering support
Finally, support. Good engineering support will, for a lot of customers, make the difference between an easy port and smooth scaling as you grow, versus struggling to ship an application that works well for all users.

At Daily, we find that we can often accelerate implementation, testing, and scaling in three complementary ways.

First, we can often save you time by offering best practices and sample code. We have sample code repositories for many common use cases and features. In an average quarter, we publish a dozen or so tutorials and explainer posts on our blog.
Second, if your use case is anything other than 1:1 video calls, it's worth a quick conversation about how to tune your video settings to maximize quality and reliability for your use case. Daily supports use cases ranging from 1:1 calls, to social apps with 1,000 participants all moving around in a virtual environment, to 100,000-person real-time live streams. The best video settings for these different use cases are all a little bit different.
Third, we can often help you debug your application code, even if your problems aren't directly related to our APIs or real-time video. We've helped hundreds of customers scale on Daily and we've seen where the sharp edges are in front-end frameworks like React. We've seen where apps tend to hit scaling bottlenecks as they grow. And we've seen how Apple app store approvals work for apps that do video and audio. We want to be a resource for our customers. We want to save your product team time.
My advice here is to talk to a vendor's developer support engineers as much as you can during your eval process. We've sometimes had customers say to us, during their vendor evaluation, "we don't want to talk to you too much because we want to make an independent decision." I always tell them the same thing: you can certainly take everything we tell you with as big a grain of salt as you want to. But not talking to eng support just makes it impossible for you to evaluate one of the important things that you should be getting from a vendor, both early on as you build or port and over the long term as you scale. You should expect great developer support. And great support can save you meaningful amounts of time and help you make meaningful improvements to your customers' video experience.
So, that's it for the five major components of vendor evaluation: reliability, quality, features, compliance, and support.
Next we'll talk about planning your implementation and evaluating resources.
Planning and resource allocation

First, it's worth thinking through whether your team knows your existing Twilio Video implementation well, and if not, what to do about that.

If engineers on your team wrote or actively maintain your Twilio Video implementation, then you're in good shape.
You almost certainly want the engineers who know your current video code just to do the port. The APIs for all major video platforms other than Zoom are similar enough that your engineers will be able to translate their existing code to the new APIs in a pretty straightforward way.
On the other hand, if your current video code was written by someone who isn't on the team anymore, consider getting help from a consultant with Twilio Video experience.
Learning the Twilio Video APIs, how your code uses them, and the APIs of another platform is ... more work. It's certainly doable, but a good consultant will likely save you significant time.
We work with several good independent dev shops at Daily. And for Twilio Video customers operating at scale, we offer a $30,000 migration credit to offset the cost for you of making the transition to Daily.

Here's my rule of thumb — my starting point — for planning a migration. The implementation work involved in porting each major part of your video tech stack will be about 2 FTE weeks.
So, for example, you have a fairly standard 1:1 telehealth app feature set. You do real-time video, a little bit of in-call messaging, and of course you have a user flow that moves patients and providers into and out of the call. But you don't do any recording and you haven't built out any BI data or observability system integrations.
If your team knows your current video implementation, porting should take one engineer about two weeks, or two engineers that work well together about a week.
On the other hand, if your video feature set is complex and includes multiple different video use cases, including recording, and you've built out custom integrations at the metrics and data layer, then a port is likely to be much closer to six weeks of FTE work.
Implementing and testing

Once you have time from engineers — and maybe an engineering manager — blocked out, you can dive into writing code!
Here are two things that I think are very important. If you only remember two things from this presentation, these two things should be it!
- Initially, do a straight port of your video implementation, changing as little as possible. Don't add new features to your application during a port. Don't do any big architectural rewrites.
- Don't build an abstraction layer. Write directly against your platform's APIs.

This advice sometimes surprises people. So let's talk about both of these in a little more detail.
Over the past eight years at Daily, we've helped thousands of customers scale, and worked closely with dozens of those customers during their initial implementations.
The projects that have struggled to ship and scale have almost all either been ports combined with rewrites and new features, or projects that tried to build an abstraction layer to isolate application code from vendor APIs.
Don't port and rewrite application code
Combining a porting project with a rewrite is, almost always, a recipe for a slower, riskier implementation. The more code you change at one time, the harder it is to debug, QA, and evaluate.
Someone on your engineering team might argue that if you're touching all the video code anyway, you should clean it up and fix all the technical debt and little issues that are on the backlog.
But don't do it. Empirically, I can tell you that the fastest, lowest risk approach is port to a new platform while changing as little of your application code as possible. Make sure everything is working as expected in production. After that, turn your attention to architecture improvements and new features!
The challenge of abstraction layers
So, if you're writing new video code anyway, why not create an abstraction layer that makes it easy to switch between platforms down the road? It turns out that designing, building, debugging, and maintaining an abstraction layer is a lot more work than doing several ports. An abstraction layer sounds like a good idea. I've had this conversation with many product teams over the years.
But every single customer we've had who set out to build an abstraction layer has abandoned the effort, either before ever getting to production with the abstraction layer, or down the road to improve code maintainability.
Also, in addition to adding risk and time to a project, using an abstraction layer prevents you from leveraging the specific strengths of a video platform. This can be okay for very simple apps. But even for simple apps, using the lowest common denominator feature set across multiple vendors is not usually a path to success.
Testing a new video implementation
Now let's talk about testing your new video implementation.
In general, if you use our recommended settings at Daily, we can confidently tell you that your video and audio will be delivered reliably to users on a very wide range of real-world networks.
But that's because we do a whole lot of testing ourselves, all the time.
We also know, because we do a lot of competitive benchmarking, and we've helped a lot of customers port to Daily, that this same level of testing isn't done by every video platform.
So I think it's worth diving into the topic of testing, just a little bit. If your vendor doesn't do this testing, your team will need to.

First, it's important to test on simulated bad networks. Developers tend to have fast machines and good network connections.
Just because things work well for your engineering team, during development, does not mean that they will work well for all of your real-world users. Your platform vendor should be able to help you test your application on simulated bad network connections. You can also work with an independent testing service like testRTC.
Here are three basic tests that are worth doing regularly all the way along during development. Together, these three tests will help you make sure that your application is ready for production.
Networking testing: regular tests with real-world conditions

First, test regularly on a cellular data connection.
Second, test in a spot in your office or house that you know has sketchy wifi coverage.
And third, test consistently with a network simulation tool that can mimic a high packet loss, low throughput network connection.
This may seem like a lot, but you will have real-world users that match all of these profiles. In all of these cases, video should degrade gracefully and audio should remain clear.
Device testing

It's also important to test on a variety of real-world devices. Android phones, iPhones, older laptops. Again, your engineering team will likely have fast machines and – for browser-based apps – will tend to test on their laptops during development, not on their phones. But for telehealth, many of your users will be on mobile devices.
Load testing
Finally, it can be valuable to do load testing of your application. This is less of a concern when porting, because you know your app already works well in production. (This is, again, another reason to do a straight port, rather than a bigger rewrite, when moving between platforms. Less new code means less surface area that you will need to test from scratch.)

If you do want to do load testing, there are some unique things about testing video apps. Most load testing tools can't instantiate video sessions.
Here again you can get help from a video-focused test platform like testRTC. Daily also has a set of infrastructure features that make testing with automated and headless video clients easy, which we affectionately call our robot APIs.
Moving traffic

When you've tested internally and are ready to move production traffic, we recommend the following sequence:
- Set up monitoring
- Train your support staff
- Move 10 opt-in customer accounts
- While monitoring, move 10%, than half, then all of your traffic

You can obviously customize these steps to your particular needs and organizational best practices.
In our experience, you will usually find at least one or two bugs in step 3, while testing with a handful of accounts that have opted into being beta testers for your new video implementation. But, generally, if you've worked closely with your vendor to test on a variety of networks and devices, step 4 goes smoothly.
Enterprise firewalls
One wrinkle here is enterprise firewalls.

If you have customers who are behind locked-down enterprise firewalls, you've probably worked with your customers' IT staff to set up configurations that allow Twilio Video traffic on their networks. Getting approval for firewall changes, and implementing and testing those changes, can be time-consuming.
So if you will need your customers to make firewall changes, start this process early.
Twilio's STUN and TURN services are not going away. These two services are a big part of firewall traversal, and they are used by multiple Twilio core products (not just Twilio Video). Daily supports using Twilio STUN and TURN services in combination with Daily. This can minimize the need to make changes to firewall configurations. If you are evaluating multiple vendors, ask about keeping your Twilio STUN and TURN configuration.
Wrapping up

Timelines for migrating a Twilio video application
So how long will all of this take? Of course the most accurate answer is, "it depends."
But, as a rule of thumb, from start to finish a port usually takes between 1 and 3 months. For a typical telehealth app, you can roughly plan on 2 weeks for each of the four phases: vendor selection, implementation planning, implementation and testing, and moving traffic. Which adds up to two months.

We have customers who have ported to Daily and moved all traffic in under a week. We also have customers who have taken 18 months to port and move all traffic.
The big thing I want to leave you with today is that porting to a new vendor is not overwhelming — it's a very manageable process.
Closing thoughts

Break the porting process down into defined phases. And do a straight port, initially, changing as little code outside your video implementation as possible.
Finally, lean on your vendor. We're here to help. If you can't get good support from us when we're trying to win your business and help you move your traffic over, you probably won't get it later. Evaluate our engineering support just like you evaluate our infrastructure and feature set.
Real-time video is a small world and I know most people in our space. All of us — Daily and all our competitors — want every customer to succeed and want to over-deliver on engineering support.
Thanks for listening.
A Q&A followed the live webinar. If you are interested in the Q&A content, please watch the video embedded at the top of this post. For more content about migrating from Twilio Video, see our Migration Resources hub. Also feel free to contact us directly at help@daily.co, on Twitter, or by posting in our community forum.
VCS is the Video Component System, Daily's developer toolkit that lets you build dynamic video compositions and multi-participant live streams. We provide VCS in our cloud-based media pipeline so you can access it easily for recording and live streaming via Daily's API. There's also an open-source web renderer package that lets you render with VCS directly in your web app --- this way, you can use any combination of client and server rendering that best fits your app's needs.
Since its introduction on Daily as a beta feature last year, VCS has gained dozens of features based on requests and ideas from our customers. We're now getting ready to take off the beta label. That means the API and feature set are very close to stable, and it's a good time to take a look at all the new stuff that the platform has added.
What you're reading now is the first in a four-part series of posts covering new features in VCS. In this initial outing, we'll be looking at two new overlay graphics options for richer dynamic visuals. We'll see how a new "highlight lines" data source can be used to provide content to the various graphics overlays. We'll also look at ways to use content behind video elements. You can now use VCS WebFrame as a full-screen live background, which can make it easier to port your existing web-based UIs to VCS for recording and streaming.
So, this first post is about new tools and options for motion graphics and background content. The upcoming second post will focus on customizing video elements and their layout, and will also explain some new debugging tools related to rendering Daily rooms in VCS.
The third post in the series will cover new ways to link data sources into a VCS composition. These will let you render chat, transcript, and emoji reactions automatically. Finally, to conclude this series, we'll be unveiling new open-source libraries and code releases that make it possible to use VCS in your own real-time apps and even offline media pipelines and AI-based automation. So it's going to be worth checking back here regularly!
New graphics overlays
Before we look at the new graphics options, let's have a quick refresher. VCS is a React-based toolkit designed specifically for video compositions. It is open source. There are two parts to the project: the core and the compositions.
The VCS Core project interfaces with the React runtime and provides built-in components like Image, Video, Text, and so on. But it's just a framework. To render something, you need a program that uses VCS. These programs are called compositions.
You could write your own composition from scratch using the VCS tools, but to make life easier, we at Daily provide a baseline composition which includes a rich set of layout and graphics features. When you start a recording or live stream on Daily's cloud, the baseline composition is enabled by default. You can control it by sending parameter values for things like changing layout modes and toggling graphics overlays.
The VCS SDK includes a GUI tool called VCS Simulator which lets you control a composition's params interactively. We provide the baseline composition's simulator online, so you can easily experiment with the various params available.
There's a lot of params already, so the simulator is quite dense! But don't be discouraged from experimenting. In this blog post, when you see a mention of a composition param such as "showBannerOverlay", you can always try it out interactively within the simulator linked above. It's the best way to get a handle of how these options really work.
Banner
Now let's take a look at the new visual components in the baseline composition, starting with Banner.
The Banner is an overlay with a title and a subtitle. In its default configuration, the Banner is placed in a spot commonly known as "lower third" in television graphics. It's a staple of TV design because it's often used to show the identity of the person speaking, like this:

You can see how "lower third" got its name — the overlay box is located in the lower third of the screen. Following the usual rules for TV videography composition, this leaves enough room above the overlay for important content like the person's face.
The above screenshot shows the default styles of the Banner component. The two fonts, text colors and background color can all be configured separately.
To display this component and set the two text values, you can use the following composition params:
call.startRecording({
layout: {
preset: "custom",
composition_params: {
"showBannerOverlay": true,
"banner.title": "Seymour Daylee",
"banner.subtitle": "CEO, Acme Widget Corporation"
}
}
});For more information on how to pass VCS composition params when starting/updating a recording or live stream on Daily, see this guide.
For details on all the composition params that are available for the Banner component, see the startRecording reference under the heading "Group: Banner".
It's possible to omit the subtitle entirely if you want just a big title. For that configuration, pass an empty string for banner.subtitle.
The Banner component can also contain an optional icon, and you change its size:

composition_params: {
"showBannerOverlay": true,
"banner.title": "Seymour Daylee",
"banner.subtitle": "CEO, Acme Widget Corporation",
"banner.showIcon": true,
"banner.icon.size_gu": 5,
"banner.icon.emoji": "🎉"
}The icon shown in Banner can be either an emoji or an image asset. The above example shows how you can set the emoji using the param. To use an image instead, you should leave banner.icon.emoji empty and pass an image name in banner.icon.assetName. Your custom image must be uploaded using the VCS session assets API.
Banner also supports fade in/out animations. These are on by default, so you'll automatically get a short fade-in transition when toggling the showBannerOverlay param. This is generally more pleasing for a viewer because it's less jarring. If you want to disable the animation, you can set the param banner.enableTransition to false.
While the Banner's default configuration is a TV-style lower third, you can change its position to anywhere on the screen:

composition_params: {
"showBannerOverlay": true,
"banner.title": "Seymour Daylee",
"banner.subtitle": "CEO, Acme Widget Corporation",
"banner.showIcon": true,
"banner.icon.size_gu": 4.5,
"banner.position": "top-right",
"banner.margin_y_gu": 1,
"banner.margin_x_gu": 1,
"banner.title.fontSize_gu": 2,
"banner.subtitle.fontSize_gu": 1.3,
"banner.pad_gu": 1.3
}The Banner is a flexible component for many kinds of designs. It can expand in both directions to fit the text, but you have control over this behavior to ensure it stays within a designated screen area. The VCS Banner component has several params that let you decide how large it can grow horizontally.
Below, the maximum width of the component is set to 30% of the viewport size, and we're displaying some unusually long text in the subtitle:

composition_params: {
"showBannerOverlay": true,
"banner.title": "Seymour Daylee",
"banner.subtitle": "CEO, Acme Widget Corporation, with some long example text here",
"banner.showIcon": true,
"banner.icon.size_gu": 4.5,
"banner.position": "top-right",
"banner.margin_y_gu": 1,
"banner.margin_x_gu": 1,
"banner.title.fontSize_gu": 2,
"banner.subtitle.fontSize_gu": 1.1,
"banner.pad_gu": 1.3,
"banner.maxW_pct_default": 30
}Note how the component expands vertically to fit all the text specified for the title and subtitle. This way you don't have to worry about whether dynamic text will fit inside the Banner graphic.
Sidebar
Whereas the Banner component is reminiscent of TV graphic design, the sidebar is probably familiar from desktop UI design. In its default configuration, the new Sidebar component in VCS renders as an overlay on the right-hand side of the screen:

call.startRecording({
layout: {
preset: "custom",
composition_params: {
"showSidebar": true,
}
}
});If you don't want the sidebar to overlap the video elements, you can easily change it so that the video layout "shrinks" to make room for the sidebar. Here's a four-person video grid next to the sidebar:

composition_params: {
"showSidebar": true,
"sidebar.shrinkVideoLayout": true
}These days it's common for live streams to be in portrait mode (and sometimes even square, for those of us who cherish compromise). The Sidebar component automatically adapts if the viewport is not landscape and moves the bar to the bottom instead. This placement is clearly better for fitting text on narrow screens:

Using params "sidebar.height_pct_portrait" and "sidebar.width_pct_landscape", you can control the sidebar's size separately for the landscape and portrait modes:

composition_params: {
"showSidebar": true,
"sidebar.fontSize_gu": 1.3,
"sidebar.height_pct_portrait": 15,
"sidebar.width_pct_landscape": 30
}Here the height in portrait mode is set to only 15%, while in landscape mode we're using a width of 30%.
The sidebar component of course also has params to change its font, text color, background color, and other settings familiar from the other visual components in the VCS baseline composition.
For details on all the composition params that are available for the Sidebar component, see the startRecording reference under the heading "Group: Sidebar".
If the content within the Sidebar component is longer than would fit on screen, it automatically scrolls to the end so that the last item stays on screen. (You can see this in the last screenshot above: it's only showing three lines because all the text doesn't fit in the narrow bar when it's set to 15% height.)
This brings up an important question: how does the Sidebar component get its content? You can see in the above screenshots that the sidebar contains a list of items. There are two text styles being used --- a base style, complemented by a special highlight style applied to one selected item.
Yet there isn't a param directly in Sidebar's settings for specifying the list of items. So where does the list come from?
Highlight lines
The secret behind the Sidebar component's highlighting capability is a new feature called highlight lines. It is actually implemented as two params in the baseline composition: highlightLines.items and highlightLines.position.
The value for highlightLines.items is multiple lines of text (separated by newline characters). By updating the value for highlightLines.position you can change the highlight, as seen in the above screenshots of Sidebar where the position was set to a value of 1, thus highlighting the second item. (If you don't want the highlight, pass a value of -1. That ensures all the items will be displayed with the base color.)
You can use this data source to display any kind of list consisting of individual text items, with or without the highlight. If a line is longer than the component's display width, it will flow automatically to the next line, so text never gets truncated.
Sidebar isn't the only component that supports display of this data. You can also display it in the TextOverlay component by specifying "highlightLines.items" for the source param. The output will look like this:

composition_params: {
"showTextOverlay": true,
"text.source": "highlightLines.items",
"text.align_horizontal": "left",
"text.align_vertical": "top",
"text.fontSize_gu": 1.9,
"text.offset_x_gu": 1,
"text.offset_y_gu": 0.2
}Using TextOverlay rather than Sidebar gives you more freedom to place the list on-screen as it's not constrained within the sidebar. Of course it obeys the various text layout options available on TextOverlay like centering, etc.
Similarly, the Banner component has a source param that provides the ability to display items from the highlight lines source. Because space is more constrained in Banner, it opts for a different kind of rendering. Instead of showing the entire list, it shows the current item and the following one, like this:

composition_params: {
"showBannerOverlay": true,
"banner.source": "highlightLines.items",
"banner.showIcon": false,
"banner.title.fontSize_gu": 2.1,
"banner.subtitle.fontSize_gu": 1.4
}
}
});Data sources are a powerful feature because they separate data from presentation. In an upcoming blog post, we'll see how you can drive these same visual components (Banner, TextOverlay and Sidebar) using various real time data sources too, not just the values from the highlight lines params.
Emojis as images
Previously when discussing Banner, we saw that the icon displayed inside the banner can be specified using an emoji string, like this:
composition_params: {
"showBannerOverlay": true,
"banner.showIcon": true,
"banner.icon.emoji": "🎉"
}The same feature is now also available for the ImageOverlay and Toast components.
For example, to render a big thumbs-up emoji as an overlay, pass it using the new image.emoji param and enable the image overlay component. Also set the aspect ratio to 1 because the emoji is a square image:
composition_params: {
"showImageOverlay": true,
"image.emoji": "👍",
"image.aspectRatio": 1
}
The Toast component has a toast.icon.emoji param that works just like the one in Banner.
Composition backgrounds
Until now, the only option available for controlling the composition's background style was the backgroundColor property available as a configuration option when starting a recording or live stream.
That property still works, but new settings in the VCS baseline composition give you easy access to two other ways to specify a background: you can use a custom image or a WebFrame embedded browser.
Still images
With the new "image.zPosition" param, you can place an image in the background. Typically you'd want it to be full-screen, as shown here:

composition_params: {
"showImageOverlay": true,
"image.zPosition": "background",
"image.fullScreen": true,
"image.fullScreenScaleMode": "fill"
}
Live WebFrame background
In addition to a still image, you can also use a web page as a background to your composition. This opens a lot of creative possibilities.
We introduced WebFrame back in June. It's a component that lets you embed live web content into a VCS composition, quite similar to how an <iframe> element works in HTML.
The baseline composition now has a "webFrame.zPosition" param that lets you place the WebFrame component behind all video elements. It works exactly like the "image.zPosition" param discussed in the previous section.
In combination with "webFrame.fullScreen", you can use this to render a web page that covers the entire background behind video layers.
This can be particularly useful if you have an existing web-based UI that you want to transform into a VCS-rendered stream/recording. The workflow is roughly as follows:
- In your web app, create some kind of "server rendering" display mode where you can customize which elements get displayed.
- In this mode, the app should only connect to your backend for whatever data is needed when streaming or recording. Disable all code that connects to media streams from a Daily room. Those will be rendered as VCS video layers, so the web app doesn't need to render them itself.
- In the UI, leave an empty space for the video layout.
- When starting a stream/recording, use the WebFrame composition params to load your web app in this display mode as the VCS background.
- Using composition params, adapt the VCS video layout to fit into the empty space in your UI.
For typical apps, this would get you to a place where you have the basic composition working on the server. But some tuning will most likely be needed to get the appearance you need.
More detailed instructions would be specific to how your app works. If you have animated elements that happen in the foreground (e.g., emoji reactions), you should replace them with a matching VCS component. We'd be happy to help you figure out the details of this adaptation!
At this point you might be asking: Why should video layers be separately rendered? Why not just render the entire UI in WebFrame? It's a very reasonable question! The short answer is that WebFrame doesn't support real-time rendering of video layers. It's meant for embedded documents and widgets like chat, not media playback.
The somewhat longer answer is that it's all about trade-offs. A web browser was never designed to be a server-side media engine. The VCS compositing model leverages the best technologies for each type of media, which enables us at Daily to offer this service in a scalable and affordable way.
And if you want a really long answer, you're in luck --- I've got a blog post coming soon about this topic. It will explain what "web page recording" really means in different contexts; the various solutions available in the market and why they tend to have fundamental reliability problems; and will also go into more detail on how you can structure an application to leverage VCS effectively.
What's next
In this post we saw several new ways to use graphics overlays and WebFrame. If you have questions or need help implementing these features in your app, don't hesitate to contact us for support.
The next post in the series will look at enhancements that apply to video layers, and some new ways to access room-level data. We'll see how we can use VCS for customizations like changing the design of a live video item based on whether the person has their audio muted. See you soon on this blog!
]]>Zoom has impressive market share in the video conferencing space. Zoom’s infrastructure and tech stack is very good. The Zoom desktop clients for macOS and Windows are easy to download and work well.
More recently, Zoom launched developer SDKs. These developer SDKs are less mature than the Zoom end-user products. In particular, the Zoom Web SDK has important feature gaps and major performance issues that developers should be aware of before attempting to port web applications to Zoom.
We've broken this post up into feature gaps relative to more established developer SDKs, performance issues relative to native WebRTC, and SDK maturity.
- Standard HTML <video> and <audio> elements aren’t supported
- Styling and positioning video tiles requires writing a lot of complex code
- Maximum video resolution is 720p
- No high-fidelity audio support
- Virtual backgrounds and background blur are not available in Safari
- No custom video or audio tracks
- No low-level video simulcast control
- Limited debugging information
- No end-to-end encryption
- No HLS live streaming or recording
- No access to raw media tracks
- No React helper libraries
How video works on the Web
Web developers today can build video, audio, and messaging applications that work on almost every computer and mobile device in the world, with no application downloads or installs required. This is made possible by an Internet standard called WebRTC, which all the major web browsers support.
Zoom’s Web SDK ports parts of Zoom’s proprietary video stack into JavaScript and WebAssembly code. Zoom does not use WebRTC. This mismatch between Zoom’s technology and video on the web means that Zoom’s Web SDK will perform poorly in browsers compared to best-in-class WebRTC video implementations.
Here is a brief overview of WebRTC. And here is a technical deep dive into three important video standards: WebRTC, RTMP, and HLS.
Web applications like Google Meet and Microsoft Teams use WebRTC. WebRTC is also used outside the web browser by native mobile applications like WhatsApp and Snap.
In fact, most real-time video and audio calls today run on WebRTC. Zoom is one of the few exceptions.
Zoom’s proprietary video vs WebRTC
Zoom’s proprietary video stack uses Zoom’s own specific implementation of the H.264 video codec, designed to run efficiently in Zoom’s macOS and Windows applications. Expertise at the video codec level gave Zoom an important advantage in the early days of consumer video conferencing. Zoom developed a reputation for “it just works” when other tools struggled to deliver a reliable video experience.
Advantages of Zoom’s proprietary approach to using H.264 include:
- The ability to make fine-grained decisions about trade-offs between video resolution, frame rate, network bandwidth, and CPU usage.
- Flexibility to optimize infrastructure and client implementations together, which can lead to significant operational efficiencies at scale.
Disadvantages include:
- Relying so heavily on a specific H.264 implementation limits options on some platforms, particularly the web browser. The WebRTC specification mandates the use of a different variant of H.264 than Zoom uses.
- Zoom is locked out of the ecosystem benefits that come from using a standard like WebRTC. Open standards generally outpace proprietary stacks in performance, features, flexibility, and security over the long term.
Today, there is no longer a gap between Zoom’s proprietary H.264 implementation versus WebRTC. In fact, WebRTC usage now far outpaces usage of proprietary stacks, including Zoom. WebRTC platforms accommodate a much wider variety of use cases than Zoom is capable of. WebRTC is used for 1:1 video sessions and 100,000-participant live streams. WebRTC can deliver good video quality on resource-constrained devices like entry-level Android phones, or can deliver 4k video at 120 frames per second on more powerful devices.
Zoom Web SDK feature gaps
Perhaps because Zoom has always prioritized development of its own Windows and macOS applications, Zoom’s Web Video SDK is relatively feature poor. In addition, technology mismatch between Zoom’s video stack and how video is implemented in web browsers limits the Zoom Web SDK’s functionality.
Developers porting from WebRTC platforms will find that many things they consider “table stakes” are missing.
Standard HTML video and audio elements aren’t supported
The Zoom Web SDK only supports video rendering via drawing to a single canvas element. The SDK automatically plays all audio streams internally through a WebAudio pipeline.
This means that you can’t use <video> and <audio> elements to play video and audio, as you would in a normal web app. Video can’t be styled using CSS. Each video tile must be drawn as a 16:9 rectangle on a single, shared canvas. (The Zoom consumer web app uses multiple canvas elements, but the Web SDK only supports drawing to a single canvas.)
This use of a canvas for video rendering also creates performance and responsiveness issues. Here is video showing how the official Zoom Web SDK demo application looks when its window is resized.
Zoom canvas resize issues
Styling and positioning video tiles requires writing a lot of complex code
Because all inbound video streams must be drawn on a single canvas and can only be drawn as 16:9 rectangles, creating anything other than a very simple UX requires a lot of code.
For example, implementing square or round video tiles — or even rounded corners — requires using techniques like drawing to an offscreen canvas.
Zoom does not provide any library support for implementing these kinds of custom, multi-pass canvas rendering operations. For example, you will need to write code by hand for double buffering, aligning pixels on the <canvas> element with other DOM elements, responding to resize events, and more.
Maximum video resolution is 720p
Zoom sets a hard limit of 720p on video resolution. This makes use cases that require high quality live streaming or cloud recording impossible.
No high-fidelity audio support
Zoom's consumer applications have support for sending higher fidelity audio, intended for music use cases. This is called "music mode" or "original sound" in the UX.
The Zoom Web SDK does not allow the audio stream to be configured for higher fidelity. The audio stream is locked to a configuration appropriate for low-bandwidth speech streams. Here is a Zoom developer forum post raising this issue.
To support music use cases, WebRTC platforms generally implement audio presents, expose multiple low-level audio parameters, or both.
Virtual backgrounds and background blur are not available in Safari
This is presumably a limitation that Zoom will fix at some point. But as of December 17 2023, virtual backgrounds and background blur are not supported in Safari.
No custom video or audio tracks
The Zoom Web SDK only allows video and audio input from system devices or a URL. Custom tracks are not supported. So it is impossible to do any local video or audio processing on a camera or mic stream before sending a track into a session.
You can’t bring your own or third-party background replacement or noise suppression solutions into your web app. You are limited to the Zoom Web SDK’s features, which are significantly less capable than offerings from, for example, Krisp.ai and Banuba.
See also No access to raw media tracks, below.
No low-level video simulcast control
Zoom provides default send- and receive-side bandwidth and video quality management. In the Zoom native clients, the algorithms for this work quite well. They do not work as well in the Zoom Web SDK and are not flexible enough to deliver the best possible user experience across the full range of real-world use cases.
For example, live streaming scenarios often require sending very high quality video layers that are appropriate for cloud recording and for users on fast network connections, alongside lower-quality fallback layers for users on slower connections. The Zoom Web SDK does not support this.
Limited debugging information
Experienced WebRTC developers rely heavily on a combination of:
- standards-based debugging and testing tools like Chrome’s webrtc-internals interface and testRTC
- platform-specific metrics and logs (see Daily’s metrics docs here, for example)
Zoom’s proprietary approach means that standard video debugging and performance optimization tools mostly aren’t useful. And the Zoom platform does not offer any detailed post-session logs or metrics data.
No end-to-end encryption
In 2020 the Federal Trade Commission accused Zoom of making substantive misrepresentations about security and encryption, including in HIPAA documentation. Zoom entered into an agreement with the FTC that mandated security improvements and that Zoom stop falsely claiming to support end-to-end encryption. In 2021 Zoom settled a related class action lawsuit for $85m.
Today, Zoom offers optional end-to-end encryption in their native macOS, Windows, and Zoom Room applications. This encryption is proprietary and it’s not possible to verify independently that Zoom is encrypting all data end-to-end.
End-to-end encryption is not supported at all in the Zoom Video SDKs for developers.
WebRTC platforms can build on top of WebRTC’s excellent, standards-based support for auditable end-to-end encryption. When a WebRTC connection is configured so that data is routed peer-to-peer, it is possible for any third party (including tech-savvy end users) to independently verify that data is encrypted end-to-end.
No HLS live streaming or recording
Zoom offers RTMP live streaming and MP4 cloud recording. Zoom does not offer HLS live streaming or recording. HLS has a number of advantages over both RTMP and MP4 for many of today’s live streaming and recording use cases.
With HLS, you can live stream directly to an audience of any size (millions of viewers). No transcoding or rebroadcasting services are needed.
Using HLS also gives you multi-bitrate recordings that are immediately playable on any device and any network connection. Again, no transcoding is needed for production-ready, on-demand streaming. Just set up the CDN of your choice in front of your HLS recordings bucket to create a cost-effective video streaming solution that’s compatible with any hosting stack.
For more information on how WebRTC, RTMP, and HLS compare, see our technical deep dive into these three widely used video protocols.
No access to raw media tracks
The Zoom Web SDK does not give developers access to raw audio or video data. This makes it impossible to build applications that do any processing of inbound audio or video. For example, you can’t do any filtering or analysis of audio, can’t implement client-side transcription, and can’t build AI-powered video features like face filters.
No React helper libraries
The React front-end framework is widely used for dynamic, single-page web apps. React offers sophisticated state management features and a powerful virtual DOM abstraction.
Some of React’s abstractions are tricky to use efficiently and safely in combination with real-time video and audio elements. For this reason, many WebRTC platforms offer React-specific helper libraries. For example: Daily’s daily-react and Vonage’s opentok-react.
Zoom Web SDK performance issues
The Zoom Web SDK uses some components of Zoom’s proprietary video stack, combined with some parts of the web browser’s native WebRTC support. This is a creative approach. But it results in high CPU usage, video quality problems, and call scaling issues.
Video quality
Zoom encodes and decodes video and audio using custom WebAssembly modules rather than the web’s standard codecs. This means that the Zoom Web SDK uses more CPU than the native browser WebRTC stack does. Zoom’s web video resolution is limited to 720p and is often lower in real-world situations, especially on older devices and most mobile phones (even current-generation iPhones).
Here’s a video showing pixelated, low resolution video quality in the Zoom Web SDK sample app running in Safari on an iPhone 15. This test is easy to replicate. Simply run the sample app and join a call from both an iPhone and a laptop.
Zoom iPhone video quality
For video and audio transport, Zoom uses WebRTC data channels rather than WebRTC media tracks.
Zoom's combination of using both non-standard encoding and non-standard media transport makes it impossible to “shape” the bitrate used for video as effectively as a native WebRTC solution.
These limitations show up as jerky video — freezes and inconsistent framerates — any time there are variable network conditions or local packet loss. For a simple, real-world test, start a video call and then walk away from your WiFi router until the signal starts to degrade. A good video calling implementation should handle moderate packet loss with very little visual impact. The Zoom Web SDK exhibits freezes and jerky video even for users on fairly good WiFi networks.
High CPU usage
Efficient CPU usage is critical for video applications. The Zoom Web SDK can’t make use of the highly optimized H.264 and VP8 codecs that are built into today’s web browsers.
As a result, on older computers and phones, the Zoom Web SDK has issues with high CPU usage and low video quality. Even on newer laptops and phones, Zoom in a web browser can’t display multiple videos in grid mode with acceptable visual performance.
Here are CPU usage tests on a fairly typical older laptop, a 2.6 GHz Dual-Core Intel Core i5 macOS machine manufactured in 2020.
In a 2-person test call, the Zoom Web SDK sample application delivers video at 360p resolution. The Safari process uses 90-100% CPU as measured by Activity Monitor. The video frame rate is inconsistent and the machine overall feels heavily loaded and laggy.
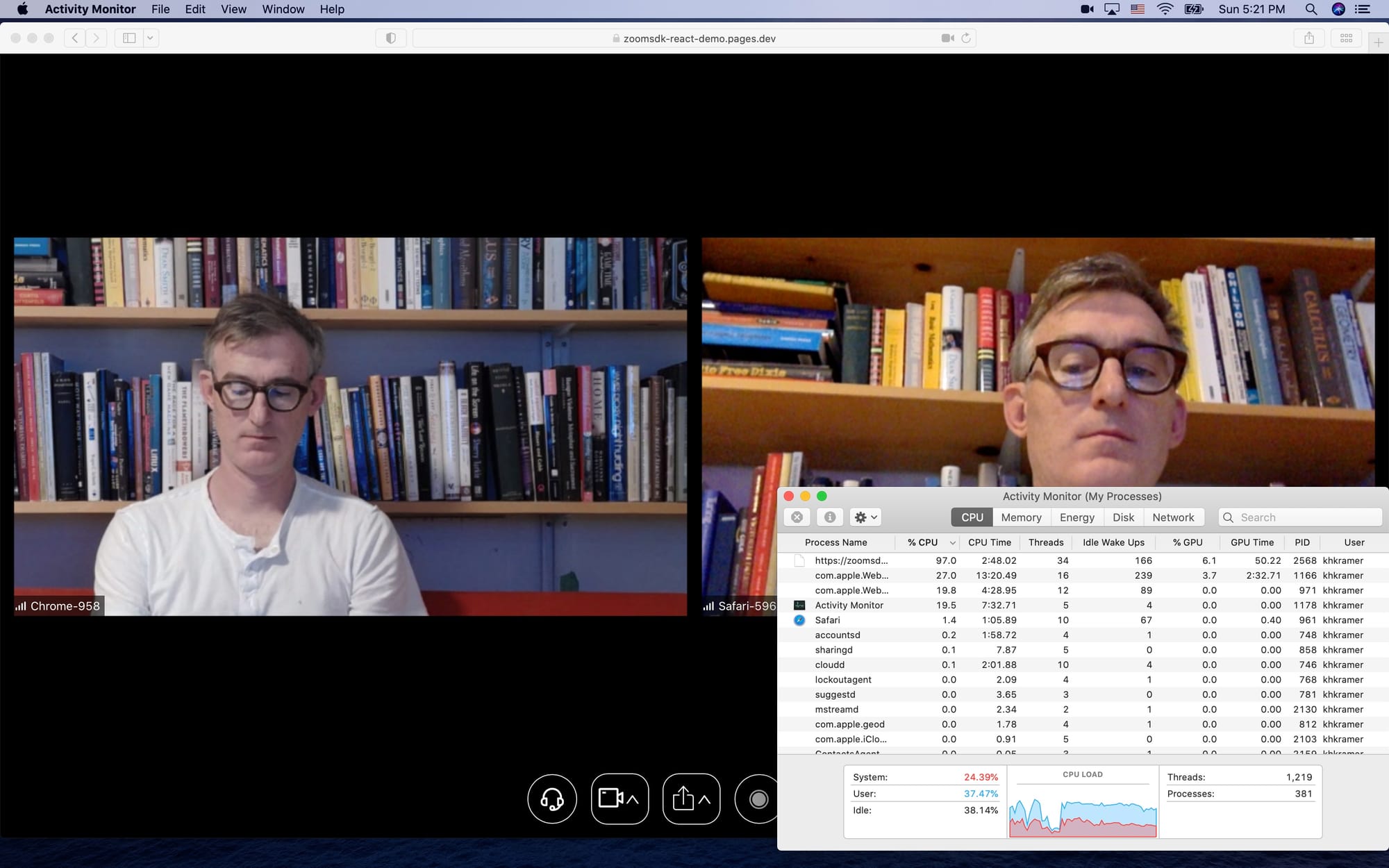
Here is the same 2-person test using Daily’s native WebRTC SDK. Configured to deliver the same video resolution as Zoom (360p), the Safari process uses 25-40% CPU. The video frame rate is consistent at 30fps. The machine feels responsive. Daily can also deliver 720p video on this machine, but CPU usage goes up to 80% and if other applications are running at the same time, the machine may start to lag. So we generally don’t recommend trying to send and receive 720p video on older devices.
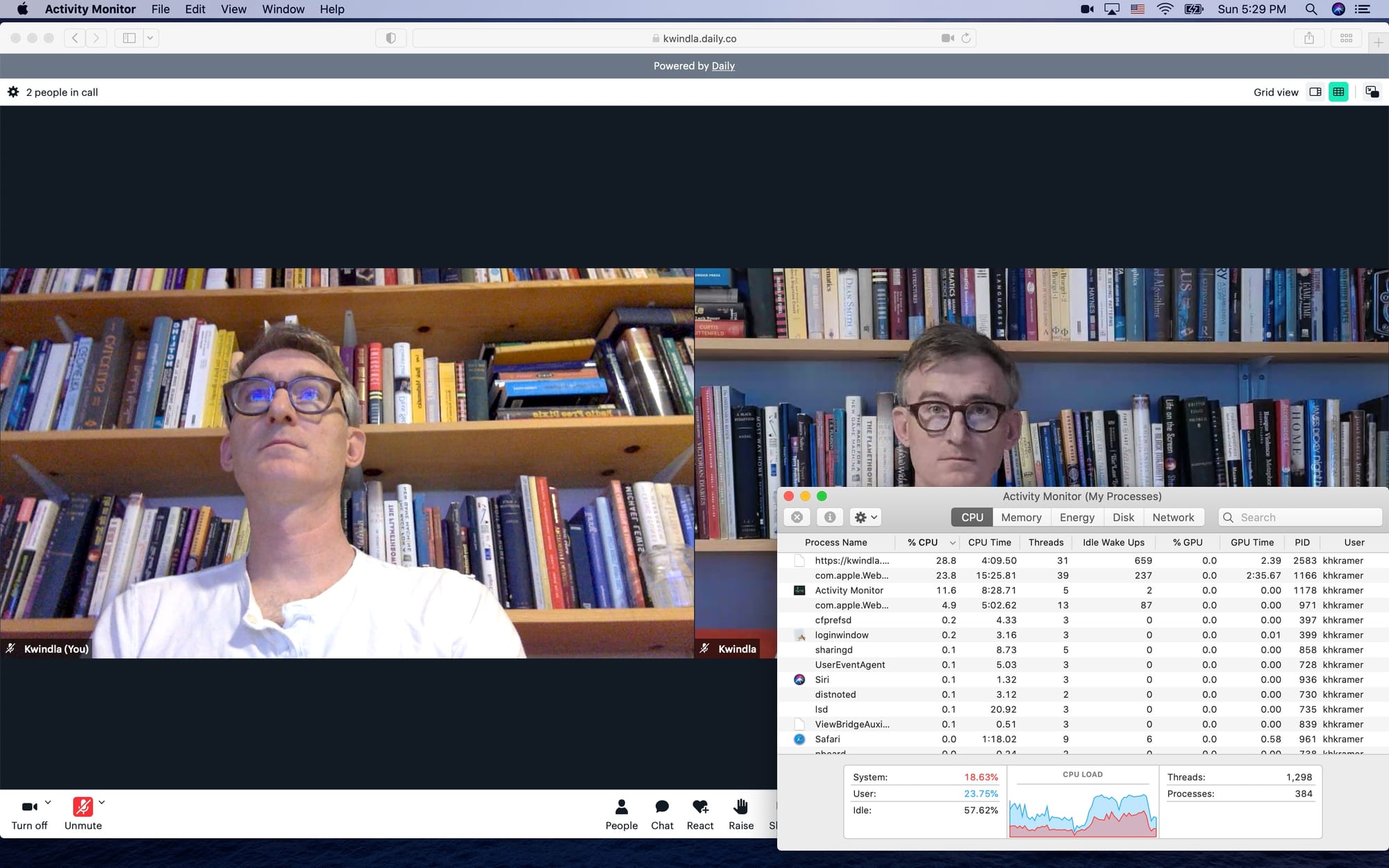
Here is a four-person call on the same machine. With the Zoom Web SDK, Safari CPU usage is 120%. The machine is very laggy. Audio and video are out of sync by several seconds. The Zoom sample application has gotten confused about the pixel resolution of the local video stream.
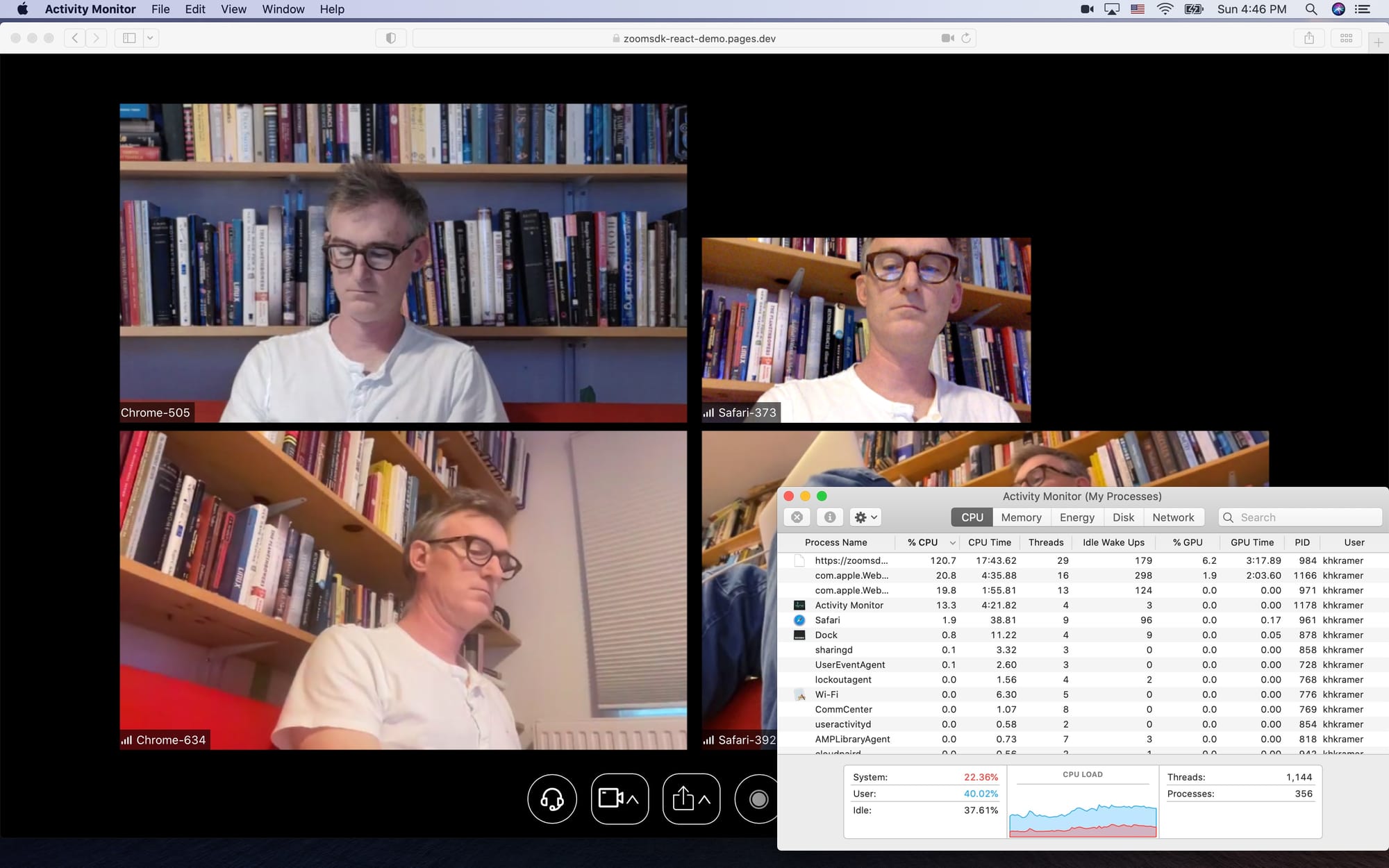
Here is the same four-person call using Daily’s native WebRTC SDK. Configured to deliver the same resolution as the Zoom Web SDK (360p), CPU usage is 70%, the frame rate is steady, and the machine is responsive.
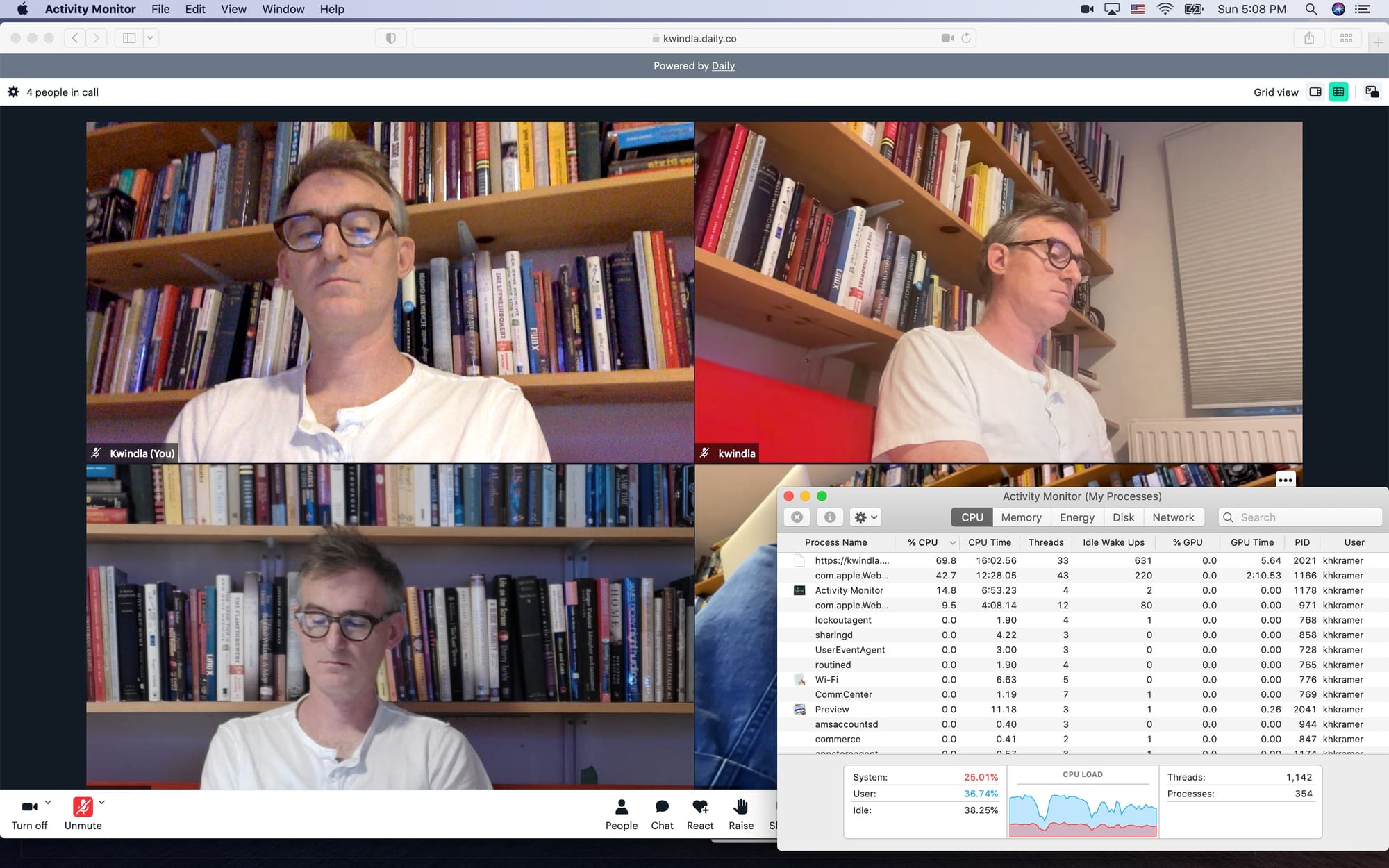
Scaling calls
The Zoom Web SDK is limited to a maximum call size of 1,000 participants. This puts interactive streaming use cases like live auctions, events with audience participation, and social games out of reach.
SDK maturity and developer tooling
Zoom has historically focused on consumer desktop applications. The Zoom Web SDK is less mature, has fewer features, and performs poorly compared to the company’s core products. It has not been widely used in browser-oriented embedded video applications.
As of the first week of December, 2023, the Zoom Web SDK shows fewer than 4,000 downloads per week on npmjs.com. Daily's npmjs download stats average about 10 times Zoom's downloads, week over week.
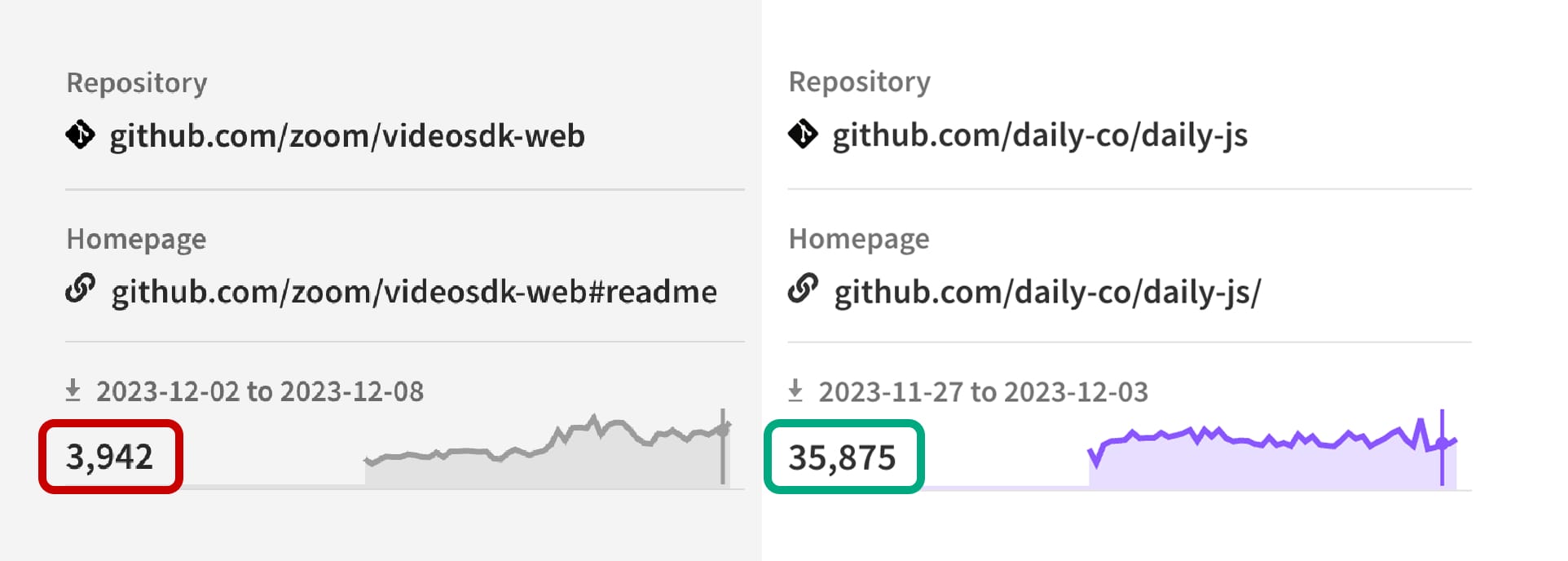
Zoom’s guides and official sample application for the Web SDK are incomplete and sometimes misleading. Code workarounds are required for the SDK to work properly on Safari. The Zoom guide for migrating from Twilio Video recommends implementing a precall test in a way that won’t be helpful for a real-time video application. Zoom’s code samples don’t cover basic topics like how to listen for important browser events.
Here’s a video showing the official Zoom web sample app leaving stale video participants in a session for more than 2 minutes.
Zoom demo app stale participants
Zoom provides little support for event logging, load testing, session analytics, integration with BI data systems, and many other things that are helpful for production coding.
Development teams building video applications that need to run in a web browser should carefully consider all of these issues before committing to building and maintaining applications using the Zoom Web SDK.
]]>We're excited to release “Talk to Santa Cat” this week, a holiday-themed mobile app designed to bring festive cheer to families and children. Featuring an AI-powered animated cat in Santa's workshop, the app lets children engage in live, voice-driven conversations with Santa Cat, adding a sprinkle of holiday magic to your family's celebrations.
The app mimics a video call to the North Pole. Just turn on your microphone and you'll connect with Santa Cat, who asks what you're hoping to get for Christmas this year. These chats, often filled with lots of fun, charm, and humor, are driven by advanced LLM (Large Language Model) technologies, ensuring each interaction is uniquely engaging.
Try it out yourself! Visit the App Store: iOS or Android.
Creating Santa Cat for families
Designed by Daily engineers who are also parents, Santa Cat sets out to be a safe and family-friendly experience. We fine-tuned the AI components so the app is both imaginative and age-appropriate, providing a space where children can safely immerse themselves in the wonders of the holiday season.
Originally, we developed the experience as a fun proof of concept. We started using it with our own families, and experienced how fun it was to share with our kids and nephews and nieces. We thought it'd be fun to put it out in the world, to share some holiday cheer.

Privacy
The app is designed with the highest level of privacy. It does not require a phone number or login information, nor does it record video or audio. It contains no ad monetization or ad analytics tracking.
Alongside creating a neat experience for families, we instead mostly built this app as a showcase for the sorts of AI experiences developers can build.
We'd love for you to share your favorite Santa Cat moments with us, either directly or on social media! Please tag us!
How does it work?
There's a lot that goes into humans having a conversation! Getting an AI-powered virtual character to sound natural, in a live voice conversation, represents several technological challenges.
Key among these are ensuring speed of transport, accuracy in Speech-To-Text (STT) and Text-To-Speech (TTS) inferences. Developers also optimize apps for real world conditions, where there's a wide range of devices and connectivity environments. We've written about this before — read a technical deep dive here.
Voice-driven virtual characters like Santa Cat also have to accommodate natural conversational elements, like interruptions, pauses, and varying speech patterns, especially with children. Engineers need to consider advanced voice activity detection (VAD), 'barge-in' interruption capabilities, and the fine-tuning of transcription models to handle diverse and spontaneous speech patterns effectively.
Of course, all of these things must happen really fast, accurately and be ready to scale to a large number of users. There’s an awful lot for engineers to consider, even if it doesn’t seem immediately obvious.
How Daily is making it easier for developers to build live virtual characters
The easiest way to get started building AI apps on Daily today is by taking a look at our StoryBot repo here. Inspired by projects such as LangChain and LlamaIndex, we’re currently evolving this repo into a new open-source framework, which handles the hard parts in a highly configurable and pluggable way. Stay tuned for more on that soon.
If you’d like to learn more about how Talk to Santa Cat was made, or are interested in learning more about Daily’s AI toolkits for voice and video, we'd love to hear from you! Please reach out to us or head on over to developer community on Discord.
]]>
How many times have you been in a video meeting and figured out who was going to keep notes, keep track of who said what, and come up with action points during the call?
Often, the mental gymnastics of coordinating discussion points and action items hampers productivity and the ability to be truly present in a conversation.
To enhance collaboration, Zoom recently launched a real-time summarization feature enabled by the Zoom AI companion.
Let's take a look at how this works and show you how to build your own AI meeting assistant using best-in-class infrastructure from Daily, Deepgram, and OpenAI.
In this post, Christian and I will show you how we created a real-time LLM-powered meeting assistant with Daily. We’ll cover:
- How to create video meeting sessions with the help of Daily’s REST API.
- How to create an AI assistant bot that joins your meeting with Daily’s Python SDK.
- How to ask your AI assistant questions about the ongoing meeting through OpenAI.
- How to manage the lifecycle of your bot and session.
What we’re building
We’re building an application that call participants can use to
- Access a real-time summary of the video call.
- Pose custom prompts to the AI assistant.
- Generate a clean transcript of the call
- Generate real-time close captions
The demo contains a server and client component. When the user opens the web app in their browser, they’re faced with a button to create a new meeting or join an existing one:
When a meeting is created, the user joins the video call. Shortly thereafter, another participant named “Daily AI Assistant” joins alongside them:
The AI assistant begins transcription automatically, and as you speak with others in the call (or just to yourself), you should see live captions come up:
When you or another user wants to catch up on what’s been said so far, they can click on the “AI Assistant” button and request either a general summary or input a custom prompt with their own question:
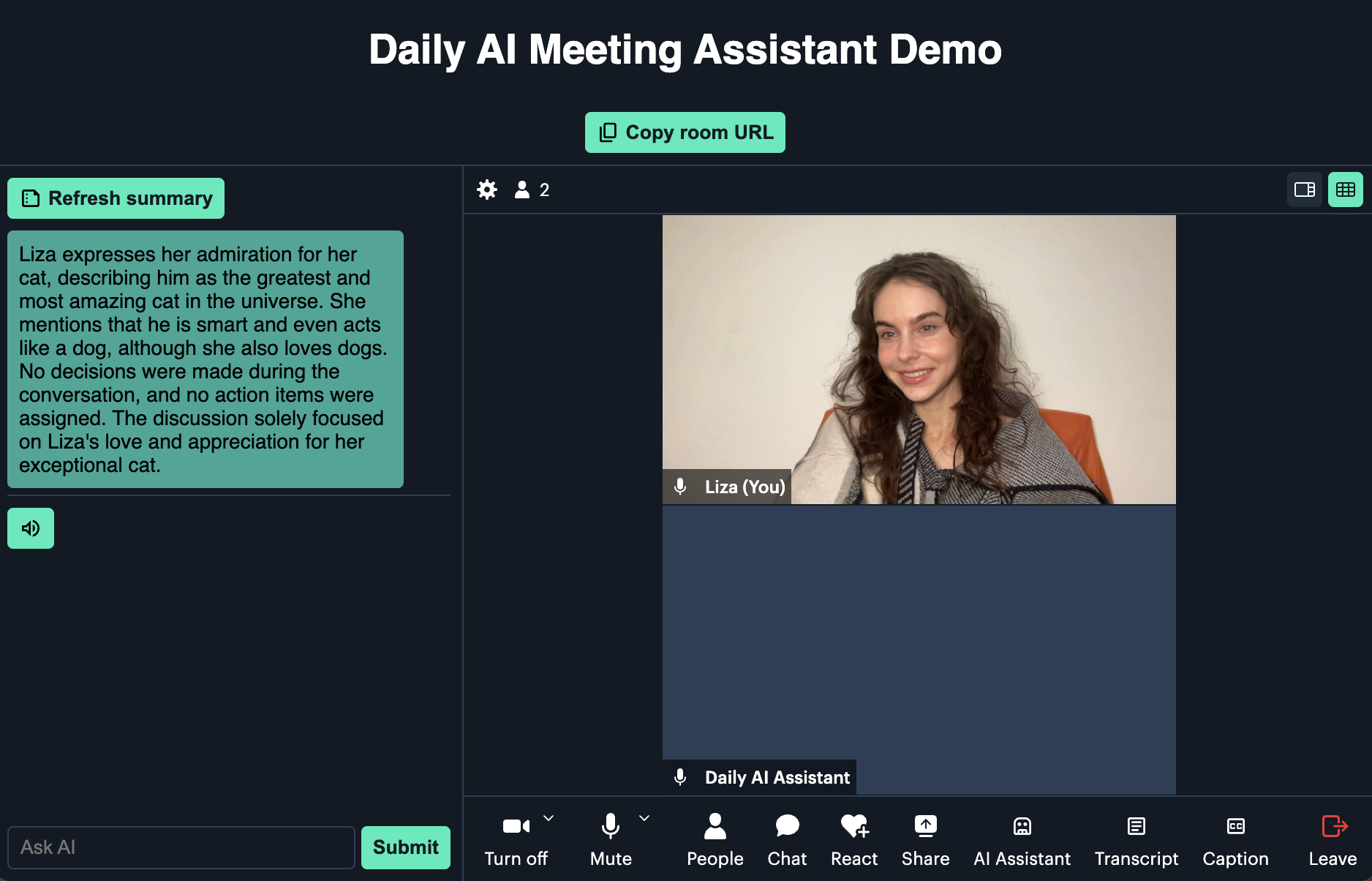
The user can also request a cleaned-up transcript of the meeting by clicking the “Transcript” button:
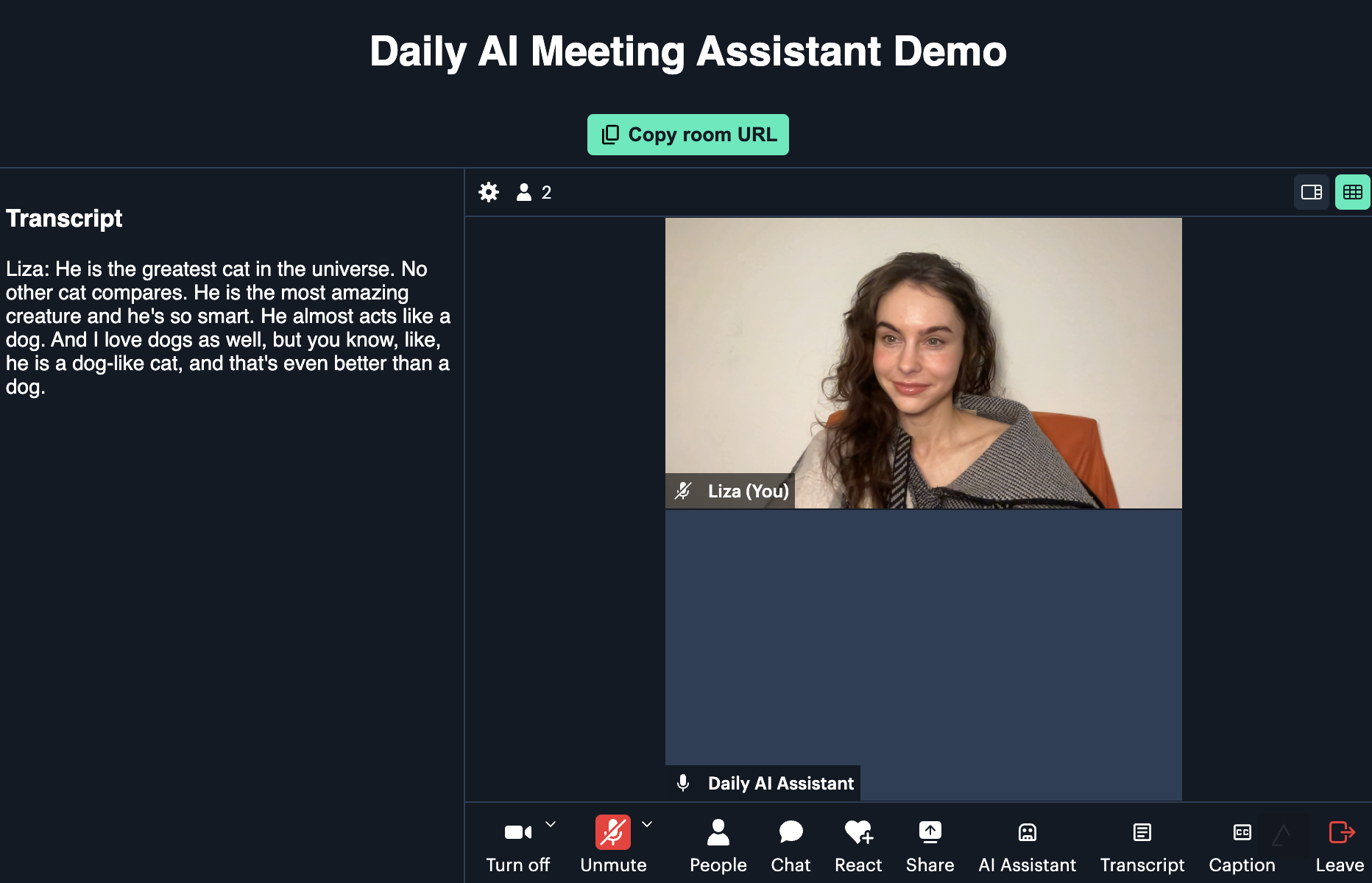
Here’s a small GIF showing the custom query feature:
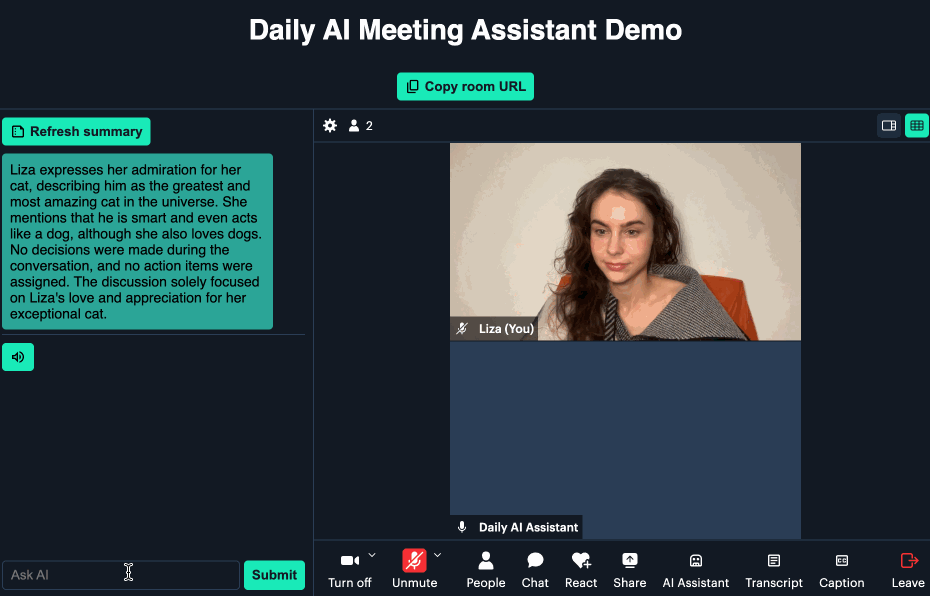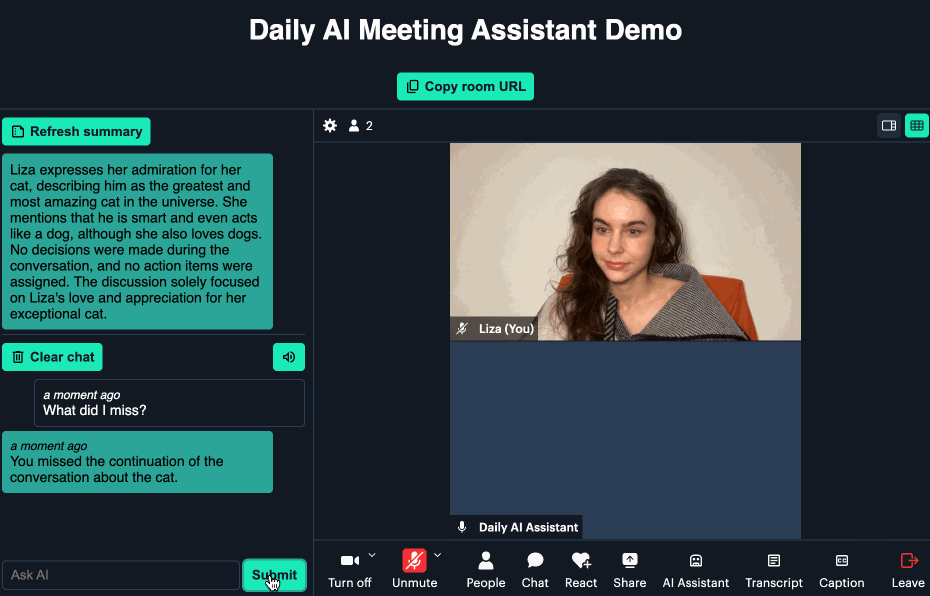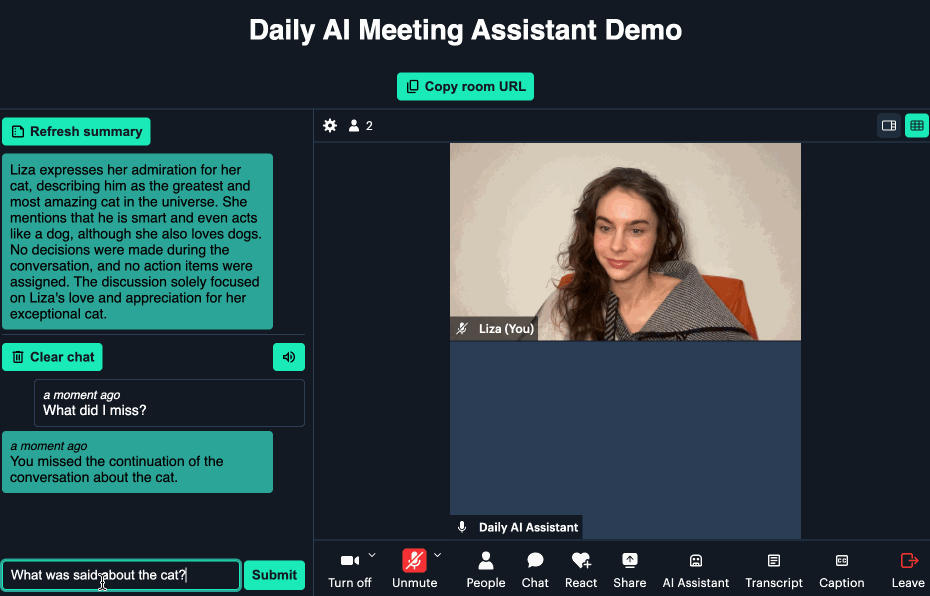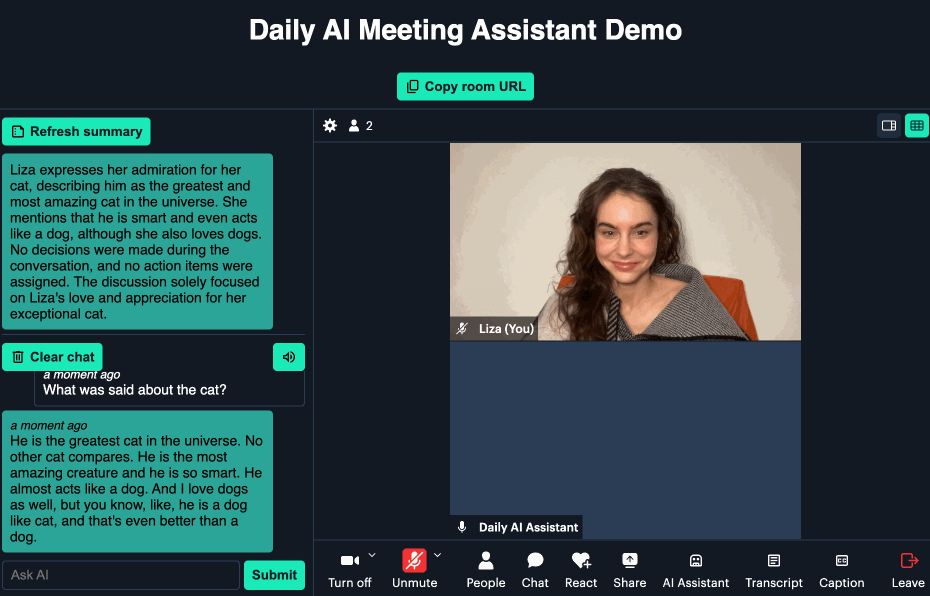
Now, let’s take a look at how to run the application locally.
Running the demo
Prepare the repository and dependencies:
git clone git@github.com:daily-demos/ai-meeting-assistant.git
cd ai-meeting-assistant
git checkout v1.0
python3 -m venv venv
source venv/bin/activate
Inside your virtual environment (which should now be active if you ran the source command above, install the server dependencies and start the server:
pip install -r server/requirements.txt
quart --app server/main.py --debug run
Now, navigate into the client directory and serve the frontend
cd client
yarn install
yarn dev
Open the displayed localhost port in your browser as shown in your client terminal.
With the demo up and running, let’s take a look at the core components.
Core components
Core server components
All the AI operations happen on the server. The core components of the backend are as follows:
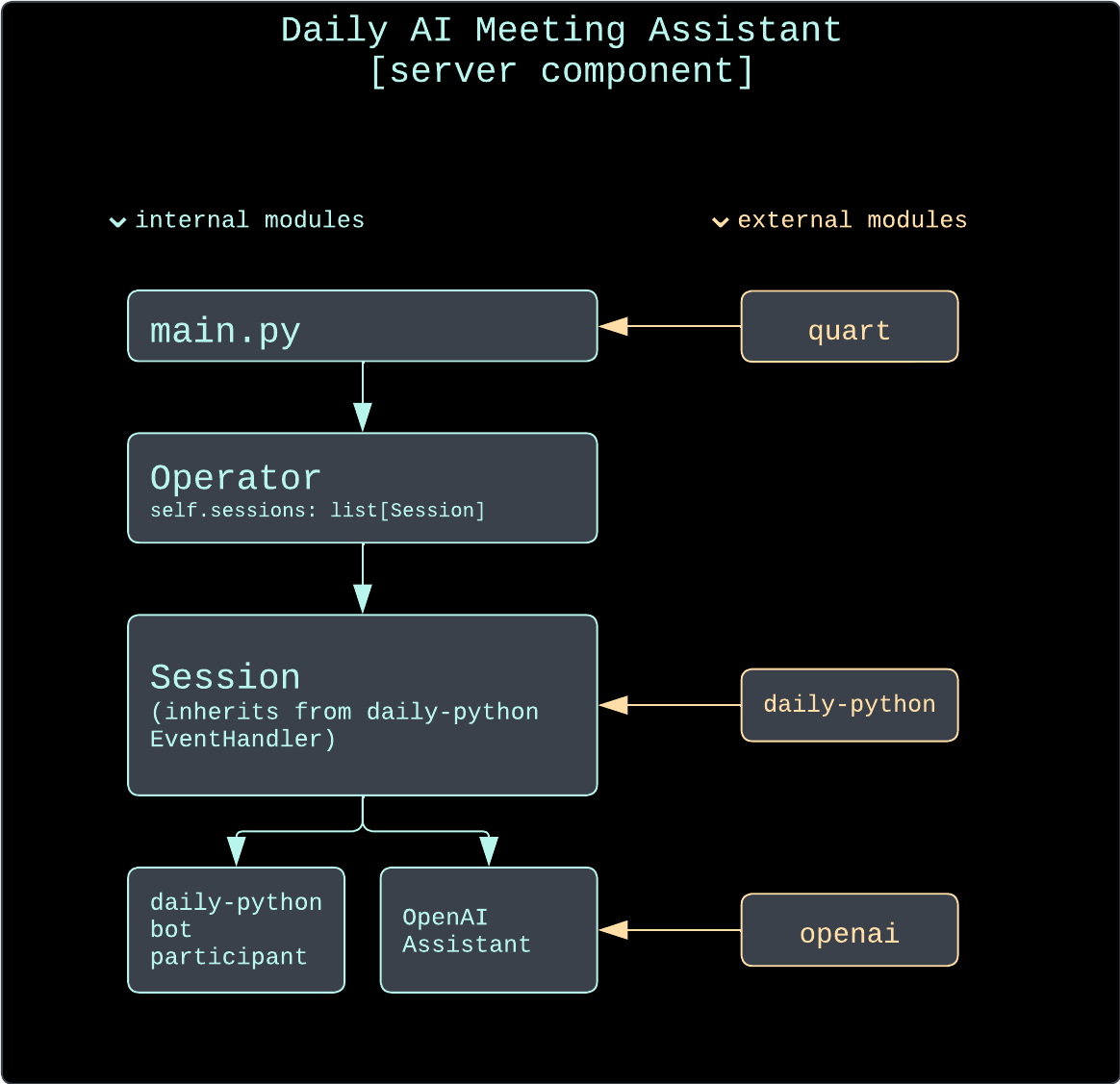
- The
Operatorclass is responsible for keeping track of all assistant sessions currently in progress. It is also the entry point to any of the sessions when a query is made using an HTTP endpoint. - The
Sessionclass encapsulates a single running assistant session. This includes creating a Daily room with Daily’s REST API and instantiating an AI assistant for it, joining the Daily room with adaily-pythonbot, keeping track of any cached summaries, and handling relevant Daily events. TheSessionclass also inherits from thedaily-pythonEventHandler, which enables it to start listening for relevant Daily events (such as meeting joins, app messages, incoming transcription messages, and more) - The
Assistantbase class defines the methods any assistant needs to implement for aSessionto work with it. - The
OpenAIAssistantclass is our example assistant implementation. It handles all interactions with OpenAI and keeps track of the context to send for each prompt.
Core client components
- The
AIAssistantReact component connects to the server, maintains the chat history and processes user input - The
TranscriptReact component maintains a cleaned up transcript of the conversation - The
Appcomponent sets up the Daily iframe, renders theAIAssistantandTranscriptcomponents, configures the custom buttons, and renders closed captions
Now that we have an overview of the core component, let’s dig into the session creation flow.
Server implementation
Session creation
A session is created when the client makes a POST request to the server’s /session endpoint. This endpoint invokes the operator’s create_session() method:
def create_session(self, room_duration_mins: int = None,
room_url: str = None) -> str:
"""Creates a session, which includes creating a Daily room."""
# If an active session for given room URL already exists,
# don't create a new one
if room_url:
for s in self._sessions:
if s.room_url == room_url and not s.is_destroyed:
return s.room_url
# Create a new session
session = Session(self._config, room_duration_mins, room_url)
self._sessions.append(session)
return session.room_url
Above, the operator first checks if a session for the provided room URL (if any) already exists. If not, or if an existing room URL has not been provided, it creates a Session instance and then appends it to its own list of sessions. Then, it returns the Daily room URL of the session back to the endpoint handler (which returns it to the user).
A few things happen during session creation. I won’t show all the code in-line, but provide links to the relevant parts below:
- If no Daily room URL has been provided, a room is created, along with an accompanying owner meeting token with which our assistant bot will join the room later.
- If a Daily room URL had been provided to the
/sessionendpoint, the session instance retrieves information about the given room and initializes a session using that room instead of creating a new one. - An
OpenAIAssistantinstance is created. There is one assistant per session. - In a new thread, the session begins to poll the room’s presence data, monitoring how many people are in the room, since there’s no point having the assistant hang around a room when it’s empty.
- When there’s at least one person in the room, the session creates a Daily call client and uses it to join the room.
- Once the session has connected to the Daily room, the
on_joined_meeting()completion callback is invoked. At this point, the session starts transcription within the room and sets its in-call user name to “Daily AI Assistant”.
The client will have received a response with the new Daily room URL right after step 1 above, meaning it can go ahead and join the room in its own time.
Now that we know how a session is created, let’s go through how transcription messages are handled.
Handling transcription events and building the OpenAI context
Daily partners with Deepgram to power our built-in transcription features. Each time a transcription message is received during a Daily video call, our EventHandler (i.e., the Session class) instance’s on_transcription_message() callback gets invoked.
Here, the Session instance formats some metadata that we want to include with each message and sends it off to the assistant instance:
server/call/session.py:
def on_transcription_message(self, message):
"""Callback invoked when a transcription message is received."""
user_name = message["user_name"]
text = message["text"]
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
metadata = [user_name, 'voice', timestamp]
self._assistant.register_new_context(text, metadata)
The self._assistant.register_new_context() method then takes the text and metadata information and formats it into a single OpenAI ChatCompletionUserMessageParam, which it adds to its context collection:
server/assistant/openai_assistant.py:
def register_new_context(self, new_text: str, metadata: list[str] = None):
"""Registers new context (usually a transcription line)."""
content = self._compile_ctx_content(new_text, metadata)
user_msg = ChatCompletionUserMessageParam(content=content, role="user")
self._context.append(user_msg)
The final context message will look something like this:
[Liza | voice | 2023-11-13 23:24:10] Hello! I’m speaking.
Now that we know how transcription messages are being registered in our assistant implementation context, let’s take a look at how to actually use them by querying the assistant.
Using the OpenAI assistant
There are two primary ways to use the configured AI assistant: to generate a generic meeting summary or to issue custom queries. Both of these types of query can be performed through HTTP endpoints or "app-message” events.
Querying entry points: HTTP and ”app-message”
To see the querying entry points implemented for the HTTP flow, refer to the /summary and /query routes. When a request is made to one of these routes, the Operator instance is instructed to find the relevant Session instance and invoke its query_assistant() method.
To see the querying entry point implemented for the ”app-message” flow, refer to the on_app_message() method within the Session class.
If the assistant is queried through HTTP requests, the answer will be sent back directly in the server’s response. If it’s queried through ”app-message” events, the response will be transmitted back through the send_app_message() call client method provided by daily-python.
Custom query or general summary
There are two types of queries an end user can make to the AI assistant:
- The user can ask for a “general summary” of the meeting.
- The user can pass in a custom query with their own question.
A “general summary” is what is produced by default if no custom query is provided to the assistant. Here’s the default prompt we opted to use to generate this general summary:
_default_prompt = ChatCompletionSystemMessageParam(
content="""
Based on the provided meeting transcript, please create a concise summary. Your summary should include:
1. Key discussion points.
2. Decisions made.
3. Action items assigned.
Keep the summary within six sentences, ensuring it captures the essence of the conversation. Structure it in clear, digestible parts for easy understanding. Rely solely on information from the transcript; do not infer or add information not explicitly mentioned. Exclude any square brackets, tags, or timestamps from the summary.
""",
role="system")
When the session’s query_assistant() method is invoked without a custom query, it will produce a general summary by default. A general summary will be regenerated no more than once every 30 seconds. If a summary that is newer than 30 seconds already exists, the session will just return that instead of sending a prompt to OpenAI again:
def query_assistant(self, recipient_session_id: str = None,
custom_query: str = None) -> [str | Future]:
"""Queries the configured assistant with either the given query, or the
configured assistant's default"""
want_cached_summary = not bool(custom_query)
answer = None
# If we want a generic summary, and we have a cached one that's less than 30 seconds old,
# just return that.
if want_cached_summary and self._summary:
seconds_since_generation = time.time() - self._summary.retrieved_at
if seconds_since_generation < 30:
self._logger.info("Returning cached summary")
answer = self._summary.content
# The rest of the method below…
If we don’t want a general summary or a cached summary doesn’t exist yet, the session goes ahead and queries OpenAI:
def query_assistant(self, recipient_session_id: str = None,
custom_query: str = None) -> [str | Future]:
# …Previously-covered logic above…
# If we don't have a cached summary, or it's too old, query the
# assistant.
if not answer:
self._logger.info("Querying assistant")
try:
answer = self._assistant.query(custom_query)
# If there was no custom query provided, save this as cached
# summary.
if want_cached_summary:
self._logger.info("Saving general summary")
self._summary = Summary(
content=answer, retrieved_at=time.time())
except NoContextError:
answer = ("Sorry! I don't have any context saved yet. Please try speaking to add some context and "
"confirm that transcription is enabled.")
# Rest of the method below…
Above, we query the assistant and then, if relevant, cache the returned summary for subsequent returns. If we encounter a NoContextError, it means a summary or custom query was requested before any transcription messages have been registered, so a generic error message is returned.
Finally, the retrieved answer is sent to the client either in the form of a string (which then gets propagated to and returned by the relevant request handler) or an ”app-message” event:
def query_assistant(self, recipient_session_id: str = None,
custom_query: str = None) -> [str | Future]:
# …Previously-covered logic above…
# If no recipient is provided, this was probably an HTTP request through the operator
# Just return the answer string in that case.
if not recipient_session_id:
return answer
# If a recipient is provided, this was likely a request through Daily's app message events.
# Send the answer as an event as well.
self._call_client.send_app_message({
"kind": "assist",
"data": answer
}, participant=recipient_session_id, completion=self.on_app_message_sent)
Now that we know how sessions are created and queried, let’s look at the final important piece of the puzzle: ending a session.
Ending a session
This demo creates sessions which expire in 15 minutes by default, but this expiry can be overridden with a room_duration_mins /session request parameter. Once a room expires, all participants (including the assistant bot) will be ejected from the session.
But what if users are done with a session before it expires, or the server as a whole is shut down? It is important to properly clean up after each session. And the most important thing to keep in mind is that you must explicitly tell your daily-python bot to leave the room unless you want it to hang around indefinitely.
In this demo, there’s no point having the bot hanging around and keeping the session alive if there is no one in the actual Daily room. What’s there to assist with if there’s no one actually there?! So, our rules for the session are as follows:
- An assistant bot only joins the room when there is at least one present participant already there.
- The
Sessioninstance waits up to 5 minutes for at least one person to show up after creating a Daily room. If no one shows up within that time, the session is flagged as destroyed and will eventually be cleaned up by theOperatorinstance - Once a session has started and a bot has joined, the session pays attention to participants leaving the call. When no more participants are present, a shutdown process begins. The session waits for 1 minute before completing this process, allowing some time for users to rejoin and continue the session.
- Once the 1-minute shutdown timer runs out, the session instructs the assistant bot to leave the room with the call client’s
leave()method. - Once the bot has successfully left the room (confirmed via invocation of our specified leave callback, the session is flagged as destroyed.
- Every 5 seconds, the
Operatorinstance runs an operation which removes any destroyed sessions from its session collection.
And now our cleanup is complete!
Considerations for production
Rate limiting and authorization
One important thing to consider is that this demo does not contain any rate limiting or authorization logic. The HTTP endpoints to query any meeting on the configured Daily domain can be freely used by anyone with a room URL and invoked as many times as one wishes. Before deploying something like this to production, consider the following:
- Who should be allowed to query information about an ongoing meeting?
- How often should they be permitted to do so?
You can ensure that only authorized users have access to meeting information by either gating it behind your own auth system or using Daily’s meeting tokens. A meeting token can be issued on a per-room basis, either by retrieving one from Daily’s REST API or self-signing a token yourself using your Daily API key. Meeting tokens can also contain claims indicating certain privileges and permissions for the holder. For example, you could make it so that only a user with an owner token is able to send custom queries to the assistant, but users with regular tokens are able to query for a general summary. Read more about obtaining, handing, and validating meeting tokens in your application.
Context token limits
By default, the backend uses OpenAI’s GPT 3.5 Turbo model, which can handle a context length of 4000 tokens. You can specify another model name in the OPENAI_MODEL_NAME environment variable, keeping potential tradeoffs in mind. For example, GPT 4 Turbo supports a whopping 120,000-token context, but we’ve found it to be more sluggish than 3.5 Turbo.
Additionally, consider optimizing the context itself. We went for the most straightforward approach of storing context in memory exactly as it comes from Daily’s transcription events, but for a production use case you may consider deprecating older context if appropriate, or replacing older context with previously generated, more concise summary output. The approach depends entirely on your specific use case.
Client implementation
With a server being set up and ready to run your personal AI assistant, it only requires a client to utilize the endpoints we’ve outlined before and incorporate them into a slick client application. We’ll be using Daily Prebuilt to take care of all the core functionality for the video call which allows us to keep the code of this demo small and focussed on integrating the AI assistant’s server component.
Setting up the app
We’ll build the demo app on top of Next.js, but it can be built using any JavaScript framework or no framework at all.
The main application is rendered on the index page route and renders the App component. The App component instantiates the Daily iframe and creates the server session. A Daily room URL can be provided through an input field or through a url query parameter and will make sure that the bot participant joins the given room. When no URL is provided, the client will join the room URL that is returned from the /create-session endpoint.
The app doesn’t send HTTP requests to the Python server directly: instead HTTP requests are routed through Next.js API routes to circumvent potential CORS issues.
In setting up the Daily iframe we’ll also mount the AIAssistant and Transcript components and configure custom buttons to:
- toggle the AI Assistant view
- toggle the Transcript view
- toggle on-screen captions
As of writing this, Daily Prebuilt doesn’t support on-screen captions out of the box, but having captions rendered on screen helps comprehend how the spoken words were transcribed to text. Eventually the transcriptions make the context for the AI Assistant.
Building the AI Assistant UI
The AI Assistant is rendered next to the Prebuilt iframe. The AIAssistant component renders a split-view consisting of a top area for a meeting summary and bottom area with a simplified chat-like UI.
The Summary button is connected to the /summary endpoint on the Python server. Once clicked, it will request a summary from the server and render it in the top area of the AIAssistant view. Since the timing can vary, depending on whether the server returns a cached response or generates a new summary, we’ll disable the button while a summary is being fetched.
The input field and Submit button allow users to ask individual questions and connect to the /query endpoint. Similarly to the Summary button, the input field and Submit button are disabled while a query is being processed. The user’s question and the assistant’s answer are then rendered in the message stream.
Finally the Transcript component automatically requests a cleaned up transcript using the /query endpoint. The component updates the rendered transcript every 30 seconds, in case new transcription lines were captured. When receiving transcript lines from deepgram, sentences might be broken into fragments. Providing a cleaned up transcript drastically improves the readability for the end-user. The Transcript component is technically always rendered to make sure that the useTranscription hook always receives the transcription app data events in order to maintain the cleaned up transcript state. We hide the component using display: none.
Closing the cycle
When the meeting ends, the Daily Prebuilt iframe is being torn down and the user is returned to the start screen.
Conclusion
In this post, Christian and I showed you how to build your own live AI-powered meeting assistant with Daily and OpenAI. If you have any feedback or questions about the demo, please don’t hesitate to reach out to our support team or head over to our Discord community.
]]>Communicating across language barriers has been a problem since long before computers even
]]>Last month, we introduced you to Storybot, a really fun demo of talking to an LLM. But when it comes to what’s possible with Daily’s AI toolkits, we’re just getting started.
Communicating across language barriers has been a problem since long before computers even existed. In The Hitchhiker’s Guide to The Galaxy, Douglas Adams solves the age-old problem with the Babel Fish, a creature that translates any speech it hears into your native language for you:
Fortunately, we can use Daily’s AI toolkits to solve this problem without having to jam anything into your ear! (Well, you can use earbuds if you want, but that’s up to you.) We’ve built a demo of live language translation using the architecture from the Storybot app. In this post, we’ll dig into the details of how it works.
If you’re looking at the scroll bar on this post and thinking you’d rather start with a high-level overview, we’ve made a video just for you:
Conceptually, the problem of live translation breaks down into four steps:
- Convert each phrase of spoken audio into text (speech-to-text).
- Translate the phrase into the desired language(s).
- Generate spoken audio of the translated phrase.
- Play back that audio for participants in the call that want to hear the translated language.
Additionally, some users may want subtitles in the original and/or translated language. More on that later.
In the Storybot post, we mentioned these three important ideas when building your own voice-driven LLM app:
- Run everything in the cloud (if you can afford to).
- Don’t use web sockets for audio or video transport (if you can avoid them).
- Squeeze every bit of latency you can out of your data flow (because users don’t like to wait).
The daily-python app
You can find the source code for the daily-python app in the server directory of the llm-translator repo.
We’ll build this with daily-python so we can run and test it locally to start, but eventually, you’ll want to deploy this to your web host of choice, or use a cloud AI platform like Cerebrium.
Step 1: Speech to text
The Daily platform handles speech-to-text for us. A simple call to start_transcription() enables Daily’s call transcription, powered by Deepgram. The transcription phrases are available as app messages, and daily-python lets us set up an event handler that gets called whenever we receive an app message. In fact, there’s even a convenience method that specifically looks for transcription messages:
# daily-llm.py
self.client.join(self.room_url, self.token, completion=self.call_joined)
# ...
def call_joined(self, join_data, client_error):
self.client.start_transcription()
# ...
def on_transcription_message(self, message):
# Ignore translators, whose names start with "tb-"
if not re.match(r"tb\-.*", message['user_name']):
print(f"💼 Got transcription: {message['text']}")
self.orchestrator.handle_user_speech(message)
else:
print(f"💼 Got transcription from translator {message['user_name']}, ignoring")
When our app receives a transcription message, it’s calling a function named handle_user_speech() in our Orchestrator instance. This is an object that, well, orchestrates the functionality of the app: It interacts with the Daily call client, as well as the various AI services we’re using in the call.
Step 2: Translation
The next step is converting the received transcript to the desired language. The orchestrator does that by creating a new thread and calling its own method, request_llm_response():
def handle_user_speech(self, message):
# TODO Need to support overlapping speech here!
print(f"👅 Handling user speech: {message}")
Thread(target=self.request_llm_response, args=(message,)).start()
def request_llm_response(self, message):
try:
msgs = [{"role": "system", "content": f"You will be provided with a sentence in English, and your task is to translate it into {self.language.capitalize()}."}, {"role": "user", "content": message['text']}]
message['response'] = self.ai_llm_service.run_llm(msgs)
self.handle_translation(message)
except Exception as e:
print(f"Exception in request_llm_response: {e}")
request_llm_response() builds an array of messages that serve as the context for GPT-4, the large language model (LLM) we’re using in this app. In this app, we only have two messages in our context: The system instruction that tells the LLM to respond by translating the next message, and the user message containing the phrase we want translated. We call the run_llm() function of our configured service, which actually makes the API call to GPT-4.
The LLM response is passed to the handle_translation() function, which we’ll look at next.
def handle_translation(self, message):
# Do this all as one piece, at least for now
llm_response = message['response']
out = ''
for chunk in llm_response:
if len(chunk["choices"]) == 0:
continue
if "content" in chunk["choices"][0]["delta"]:
if chunk["choices"][0]["delta"]["content"] != {}: #streaming a content chunk
next_chunk = chunk["choices"][0]["delta"]["content"]
out += next_chunk
#sentence = self.ai_tts_service.run_tts(out)
message['translation'] = out
message['translation_language'] = self.language
self.enqueue(TranslatorScene, message=message)The OpenAI Python SDK supports streamed responses, where instead of waiting to generate an entire sentence or paragraph, we get a single word at a time. If you’ve used ChatGPT in the browser, you’re probably familiar with the way the words appear quickly, one after another; the chunked API response works the same way. We want to generate the entire translated phrase as a single chunk of audio, though, so we wait until we’ve received all of the chunks before the next step.
Step 3: Text to speech
Generating audio is where we introduce one of the most important parts of the architecture: Scene playback.
daily-python allows us to do lots of things asynchronously—LLM completions, audio generation, image generation and more—but the scene architecture makes sure we don’t try to play back three different audio chunks at once. Let’s dig into how it works.
When the orchestrator has a new piece of content it wants to play back, it enqueues a new Scene. Each scene has two methods: prepare() and perform(). As soon as a new Scene instance is enqueued, it starts running its prepare() method asynchronously. This is where we do things like fetching audio from the text-to-speech API, or Storybot asking DALL-E to generate an image based on the prompt we’ve created.
The orchestrator can queue a bunch of scenes in quick succession, and they’ll all invoke prepare() immediately, so they’re hopefully ready to go by the time their perform() method is called.
Step 4: Audio playback
Speaking of which, as soon as the orchestrator starts scene playback, it will grab the first Scene in the queue and call its perform method. The perform method runs synchronously, one at a time in the order the scenes were queued. Each scene’s perform method waits for its prepare method to complete, if necessary, and then plays its video and audio.
In this demo, we’re taking advantage of the fact that Deepgram returns translations separately for each participant in the call. The translator app supports using Azure Speech or PlayHT for text-to-speech generation, and both services support many different simulated voices, so we’re using a different voice for each unique participant ID. Since one Python process handles each different translated language, the Scene architecture prevents the translated voices from speaking over each other, even if the original conversation had a bit of overlap.
Now, if you were to start three different translators for French, Spanish, and Japanese, and then join a call in Daily Prebuilt, you’d hear pure chaos—every time someone spoke, you’d hear it repeated in three languages! We’ll handle that problem with some flexibility from daily-react in the client app.
The client app
You can find the source code for the daily-python app in the client directory of the llm-translator repo.
The client app is built from our daily-react example app, with a few important changes. First, we’ve added dropdowns to the “hair check” screen to select the language you’re speaking, as well as the language you’d like for transcripts and audio:
In App.js, we set up an event listener to send our language settings to everyone else on the call when we join the meeting, and request for everyone else to send us their language settings. This is similar to how we sync chat history in Daily Prebuilt:
// App.js
callObject.once('joined-meeting', () => {
// Announce my language settings for everyone on the call,
// since daily-python doesn't support session data yet
callObject.sendAppMessage({ msg: 'participant', data: { lang: lang.local } });
callObject.sendAppMessage({ msg: 'request-languages' });
});
This way, everyone knows what language I’m speaking, and I know what translators are available.
We added a Subtitle component to the Tile component. Subtitle watches for app messages containing translations in the desired language, and displays them on the speaker’s video tile:
// components/Subtitle/Subtitle.js
const sendAppMessage = useAppMessage({
onAppMessage: (ev) => {
if (lang.local?.subtitles === ev.data?.translation_language && ev.data?.session_id === id) {
setText(ev.data.translation);
if (textTimeout.current) {
clearTimeout(textTimeout.current);
}
textTimeout.current = setTimeout(() => {
setText('');
}, 7000);
}
},
});We handle the audio in a useEffect hook in the Call component. Since each participant (humans and translators) gets their own audio element on the page, we can loop through them and set their volume levels, based on the language information we got from the app messages when we joined the call. Here’s what we do for each one:
- If this is a person and they’re speaking the language I want to hear, set them to full volume. Otherwise, lower their volume so I can still hear when they’re talking, but I’ll be able to hear a translator over them.
- If this is a translator and it’s outputting a language I want to hear, set it to full volume. Otherwise, mute it.
Here’s the code:
audioTags.forEach((t) => {
if (t.dataset.sessionId) {
if (lang.remote[t.dataset.sessionId]) {
// this is an audio tag for a remote participant
const langData = lang.remote[t.dataset.sessionId];
// if their spoken language isn't what I want to hear, turn them down
if (langData.spoken !== lang.local.audio) {
t.volume = 0.1;
} else {
t.volume = 1;
}
} else if (lang.translators[t.dataset.sessionId]) {
// This is the audio tag for a translator
const langData = lang.translators[t.dataset.sessionId];
if (langData.out === lang.local.audio) {
t.volume = 1;
} else {
t.volume = 0;
}
}
}
});
There’s still work to do to integrate this into your application. For example, you may want to adjust the speed of the generated audio to keep it from drifting too far behind the original speech. When using the Azure backend, you can adjust playback speed with the “prosody” element, as shown in the run_tts() function in services/azure_ai_service.py:
ssml = f"<speak version='1.0' xml:lang='{lang}' xmlns='http://www.w3.org/2001/10/synthesis' " \
"xmlns:mstts='http://www.w3.org/2001/mstts'>" \
f"<voice name='{voice}'>" \
"<mstts:silence type='Sentenceboundary' value='20ms' />" \
"<mstts:express-as style='lyrical' styledegree='2' role='SeniorFemale'>" \
"<prosody rate='1.05'>" \
f"{sentence}" \
"</prosody></mstts:express-as></voice></speak> "
Conclusion
We think the implications of this use case are massive. Live translation can democratize communication in all sorts of contexts: patient care, virtual events, education, and more. We hope this ‘deep dive’ post helps you understand how you can start using daily-python to bring AI into real-time video and audio in all sorts of interesting ways.
What new, voice-driven applications are you excited about? Our favorite thing at Daily is that we get to see all sorts of amazing things that developers create with the tools we’ve built. If you’ve got an app that uses real-time speech in a new way, or ideas you’re excited about, or questions, please ping us on social media, join us on Discord, or find us online or IRL at one of the events we host.
]]>If you are a virtual service provider–like an ed-tech, virtual events, or even telehealth platform–chances are you have a trove of video content you would like to classify and query. Imagine asking an AI assistant about something that happened at a recorded event and getting an answer back in seconds. This can save considerable time and energy, negating the need to trawl through the video or transcript and dig up information by hand.
Let’s take a look at this important AI application by showing you how to create conversational search functionality for a video content library. In this post and accompanying demo, I’ll show you how to upload your own video meetings or fetch them automatically using Daily’s REST API, and then ask your personal AI librarian questions about what was discussed within those videos.
We’ll do this by building an application that enables users to build and query a vector store using manually-uploaded video files or Daily cloud recordings. This post will cover:
- Core concepts: what even is a vector store?
- How the demo works from an end-user perspective
- Running the demo locally
- The tech stack and architecture
- The core parts of the implementation
But first, let’s brush up on some basic terminology. If you’re already familiar with the concept of vector stores and retrieval-augmented generation (RAG), feel free to skip this next part.
The basics: What is this even?
What is a vector?
For the purposes of this post, a vector is a representation of data in a format that AI can parse and “understand”. In the context of AI applications, we often talk about vector embeddings. Vector embeddings are just a way to capture semantically useful data in vector format.
What is a vector store?
A vector store also known as a vector database, is a place to store vectors. This can be pretty much anything, but for this demo I’ve used Chroma, a leading open-source embedding database that is specifically designed to power AI applications. We like Chroma for several reasons, including:
- The API design is clean and easy to use. This enables streamlined direct usage as well as integration with Retrieval-Augmented Generation (RAG) frameworks like LlamaIndex.
- All of its core functions are flexible and customizable.
What is retrieval-augmented generation (RAG)?
Large language models like GPT-4 make many new kinds of natural language interaction possible. But what if you want to leverage the capabilities of LLMs in conjunction with your own data – in our example today, your video recordings?
Retrieval-augmented generation (RAG, for short) is a strategy for using large language models to search, summarize, and otherwise process new data that wasn’t in the LLM’s training set.
The retrieval in RAG refers to fetching relevant data from a data store. Here we’re using Chroma. The generation in RAG refers to prompting an LLM to generate useful text. The LLM we’re using is GPT-4.
To implement the RAG pattern, we’re using a data framework called LlamaIndex. LLamaIndex provides helper functions and useful abstractions that make it easier to ingest, index, and query data of various kinds.
Now that we know the basics, let’s dig in.
What we’re building
The main interface of the demo is a small front-end component that looks like this:
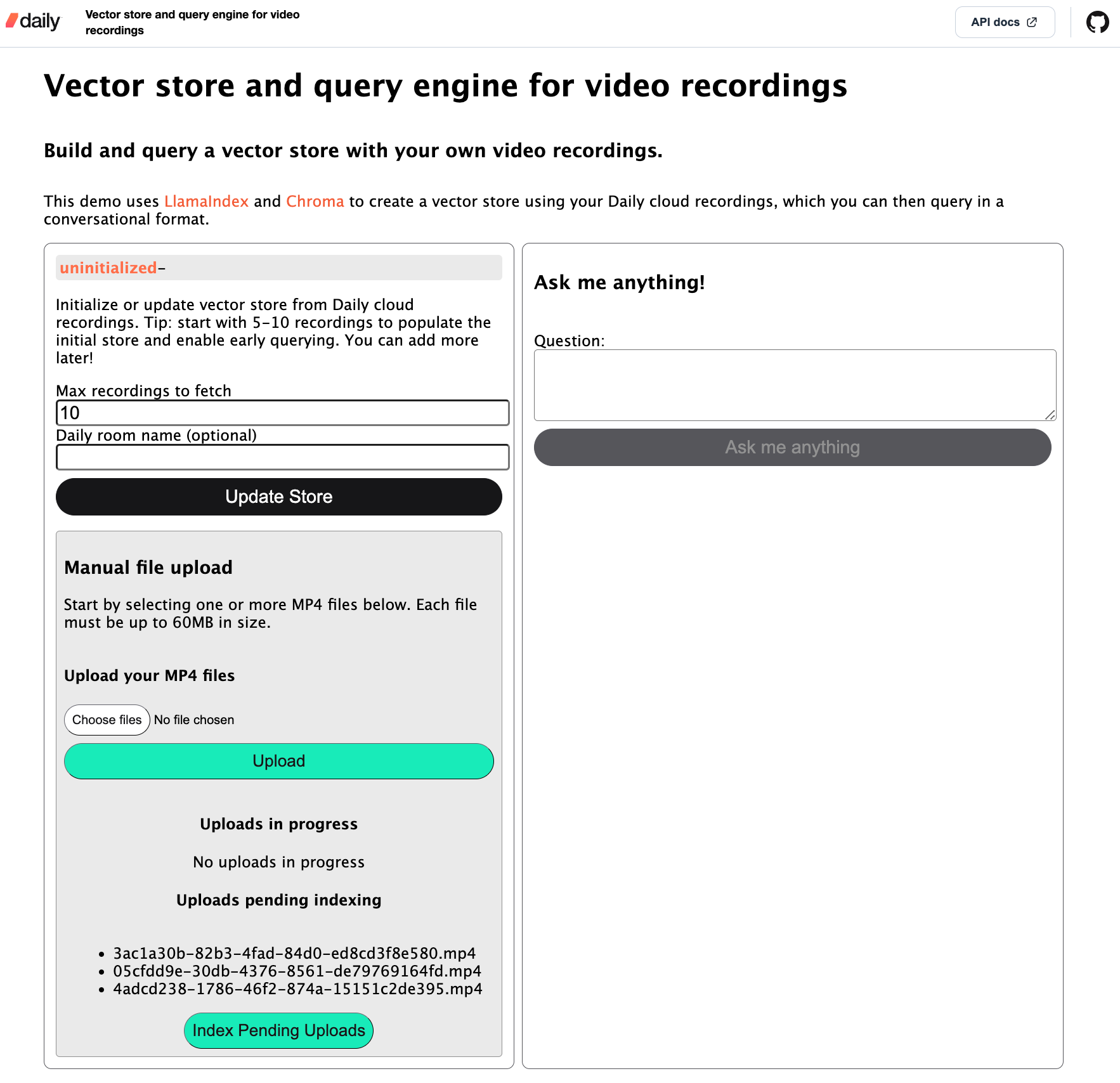
I’ll focus on the Daily cloud recordings store population flow in this post because I think it’s the most convenient for the user.
When the user opens the app in their browser, they start by creating a vector store in the left-hand column. They specify how many cloud recordings they want to index for this initial store creation and, optionally, a Daily room name for which to pull recordings. If a Daily room name is not specified, the server will pull in recordings from all rooms on the domain. Once index creation has been started, the relevant status will be shown on the client:
Depending on the size of your recordings, this step can take a while! I suggest starting with 5-10 recordings to begin with if you just want to try the store out quickly. You can update it with more data later!
Once the initial store creation is done, the store status is updated in the UI and the “Ask me anything” button on the right-hand side is enabled:
The user can then ask a question about the indexed recordings and, if relevant data exists, see an answer:

At this point, the user can also choose to index more recordings in the store to build up the collection of usable data. While the store is being updated, it can also be queried:
On the backend, the store is persisted to disk—so you can restart the server and load in your existing store.
Ok, what about manual uploads?
I’ve configured the server to permit manual uploads of up to 60MB per file for the purposes of this demo. You can configure this if desired, but I suggest sticking with small files if using manual uploads because you’ll have a much more responsive result for demonstration purposes!
The manual upload workflow is in two steps: You first upload the files and then index the files. Once a file is fully uploaded to the server, it will be shown in a file list within the UI. When you click “Index Pending Uploads”, all of those pending files will be indexed in bulk.
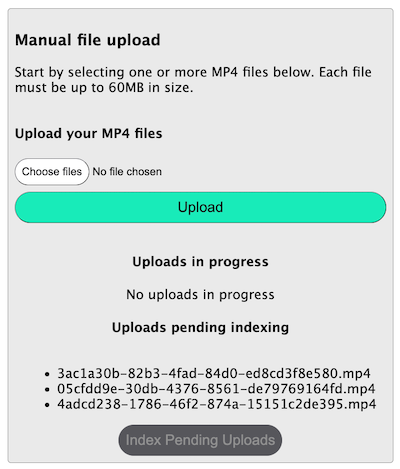
Now that we know the usage basics, let’s take a look at how to run the demo locally.
Running the demo locally
Prepare the dependencies
To run the demo locally, be sure to have Python 3.11 and FFmpeg installed. You will also need an OpenAI API key.
Once you’ve got those, run the following commands (replacing the python3 and pip3 commands with your own aliases to Python and pip as needed):
# Clone the git repository
git clone https://github.com/daily-demos/recording-vector-store.git
cd recording-vector-store
git checkout v1.0
# Configure and activate a virtual environment
python3 -m venv venv
source venv/bin/activate
# Install dependencies
pip3 install -r requirements.txt
Configure the environment
Once the requirements are installed, copy .env.sample into an .env file in the root of the repository. Do not submit the .env file to source control!
The only variable you have to set here is OPENAI_API_KEY. The rest are optional, but I really recommend you try this demo out with Daily cloud recording integration and Deepgram transcription by setting the DAILY_API_KEY and DEEPGRAM_API_KEY environment variables.
Start the server and client
Finally, start your server and client by running the following commands in two separate terminals within your virtual environment:
# Start the vector store management server
quart --app server/index.py --debug run
# Serve the front-end
python -m http.server --directory client
Open your web browser of choice (I suggest Chrome) to the localhost address shown in the second terminal window above. It will probably be http://localhost:8000.
Now that we’ve got the app running, let’s see what’s happening under the hood.
The tech stack
- Vanilla JavaScript for the client.
- Python for the server.
- Quart for the processing server (similar to Flask, but designed to play nice with asynchronous programming).
- LlamaIndex with an OpenAI API key for generating and querying a vector store and index.
- Chroma for the database backing the vector index.
- Daily’s REST API to fetch cloud recordings.
- Local Whisper model or Deepgram’s Python SDK for transcription.
moviepyto extract audio from original video files when needed.
Demo architecture
For this post, I’ll focus on the server component of the demo as that is primarily where the fun AI stuff happens. I will briefly cover how this is all tied together on the client at the end, and also encourage you to check out the client-side implementation on GitHub.
API routes
Below are all the routes the client will use to interact with the server.
POST /db/index: Creates a new vector store and initializes a vector index, or updates the existing index with new data.POST /db/query: Queries the existing index with the user’s input and returns an answer.POST /upload: Uploads video files to the server, which can later be used to index the files (note that file upload and indexing are separate operations).GET /status/capabilities: Returns the capabilities of the server, in this case used to determine whether Daily cloud recording indexing is available (i.e., whether the Daily API key has been configured in the server environment).GET /status/db: Returns the status of the vector store (i.e., whether it is initialized, updating, ready for indexing, or in a failure state).
Core components
- The primary workhorse of this demo is the
Storeclass, which handles all vector store operations. - The
Configclass handles all environment configuration (third-party API keys, destination directories for uploads, transcripts, index storage, etc) - The
Transcriberbase class defines some abstract methods that the Deepgram and Whisper transcription classes implement. This also enables you to add your own transcriber. - The
dailymodule handles fetching of Daily recordings. - The
mediamodule handles things like manual file upload and audio extraction.
Store operations
All vector store operations take place in src/server/store.py. They include:
Before I get into the index creation itself, let’s take a look at what data we’re actually going to be basing our vector store on, and how it is obtained.
Data preparation
The raw data we start out with is a video file. The final output that is inserted into the index is a transcript of the discussion for each video. The way this happens is slightly different depending on whether you use Deepgram or a local Whisper model.
Transcribing Daily recordings with Deepgram
Deepgram provides the ability to transcribe a video recording straight from a publicly-retrievable URL. So when indexing Daily cloud recordings with Deepgram, I opted not to download the recording at all for this demo—instead, I fetch the recording’s access link from Daily’s REST API and feed that to Deepgram’s Python SDK for transcription:
def transcribe_from_url(self, api_key: str, recording_url: str) -> str:
"""Transcribers recording from URL."""
print("transcribing from URL:", recording_url)
deepgram = Deepgram(api_key)
source = {'url': recording_url}
res = deepgram.transcription.sync_prerecorded(
source, self.get_transcription_options()
)
return self.get_transcript(res)
Transcribing Daily recordings with Whisper
If you opt for the local Whisper transcriber, you’ll need the video file to be available locally on the server for transcription. In that case, we’ll also fetch the recording’s access link from Daily’s REST API, but instead of sending it off to a third-party API, we’ll download the file locally.
Once the video file is on the server, I strip the audio into its own WAV file and send that off to my Whisper transcriber.
Transcribing manually-uploaded files
If using manually uploaded files with Deepgram as opposed to Daily cloud recordings, the workflow followed is the same as the Whisper workflow described above.
Once transcripts are created, they are stored in a directory on the server (of course in a production environment you may choose to use another method of storage) and inserted into the vector store.
Creating an index
So—you start with a totally uninitialized vector store and no index to use with it. You go to the front-end and initialize store creation. Now what?
The index creation or update route invokes the following index creation or update method in the Store class:
async def initialize_or_update(self, source: Source):
"""Initializes or updates a vector store from given source"""
# If an index does not yet exist, create it.
create_index = not self.ready()
if create_index:
self.update_status(State.CREATING, "Creating index")
else:
self.update_status(State.UPDATING, "Updating index")
try:
# Transcribe videos from given source.
if source == Source.DAILY:
await self.process_daily_recordings()
elif source == Source.UPLOADS:
await self.process_uploads()
# If index creation is required, do so.
if create_index:
self.create_index()
self.index.storage_context.persist(self.config.index_dir_path)
self.update_status(State.READY, "Index ready to query")
except Exception as e:
msg = "Failed to create or update index"
print(f"{msg}: {e}", file=sys.stderr)
traceback.print_exc()
self.update_status(State.ERROR, msg)Above, I set a boolean indicating whether I am creating an index or not. create_index will be True if an index does not already exist on the Store instance.
Next, I update the store status appropriately to indicate whether the index is being created or updated.
From there, depending on the given source (Daily recordings or manual uploads), I process the relevant videos. “Processing” here refers to the data preparation I mentioned above: transcribing each relevant video and saving it to a transcripts folder on the server. I suggest checking out this implementation on GitHub, to see how multiple recordings are downloaded (if needed) and transcribed using a ThreadPoolExecutor.
Finally, once all the transcripts are generated, I call self.create_index():
def create_index(self):
"""Creates a new index
See: https://gpt-index.readthedocs.io/en/latest/examples/vector_stores/ChromaIndexDemo.html
"""
# Get all documents from the present transcripts
documents = SimpleDirectoryReader(
self.config.transcripts_dir_path
).load_data()
vector_store = self.get_vector_store()
storage_context = StorageContext.from_defaults(
vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
self.index = index
- Above, I first instantiate a LlamaIndex
SimpleDirectoryReader()with my transcript directory and use it to load all the transcripts as Documents. - I then get a Chroma vector store with
self.get_vector_store()(which I’ll go through shortly). - After retrieving the vector store, I create a storage context and, finally, a vector store index.
Let’s take a quick look at the get_vector_store() method mentioned above:
def get_vector_store(self):
"""Returns vector store with desired Chroma client, collection, and embed model"""
chroma_client = chromadb.PersistentClient(
path=self.config.index_dir_path)
chroma_collection = chroma_client.get_or_create_collection(
self.collection_name)
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
vector_store = ChromaVectorStore(
chroma_collection=chroma_collection, embed_model=embed_model)
return vector_store
Basically, you create a Chroma client and a collection. You then specify your embed model and, finally, instantiate ChromaVectorStore().
So now that a vector store is created and persisted, how do you query it?
Querying our new vector store
Querying our new index is pretty straightforward. I do this in the query() method on my Store class, which takes a query string as a parameter:
def query(self, query: str) -> Response:
"""Queries the existing index, if one exists."""
if not self.ready():
raise Exception("Index not yet initialized. Try again later")
engine = self.index.as_query_engine()
response = engine.query(query)
return response
Above, I take the currently loaded index and retrieve it as a query engine. This is a LlamaIndex interface that lets you ask questions about your stored data. The query value here will be whatever the user’s input was on the frontend.
The return type of engine.query() is Response, which contains the actual answer along with some metadata. For this demo, I am only consuming the Response.response property (i.e., the actual textual answer to the query).
Updating the vector store
The initialize_or_update() method we covered above handles store updates as well. It does so by checking if an index exists after transcribing each recording and invoking index.insert() if so:
def save_and_index_transcript(
self,
transcript_file_path: str,
transcript: str):
"""Save the given transcript and index it if the store is ready"""
# Save transcript to given file path
with open(transcript_file_path, 'w+', encoding='utf-8') as f:
f.write(transcript)
# If the index has been loaded, go ahead and index this transcript
if self.ready() is True:
print("Indexing transcript:", transcript_file_path)
doc = Document(text=transcript)
self.index.insert(doc)
So if this step is run during index creation, the transcript will simply be saved to disk (and then all transcripts will be indexed in one go as a final step). If the step is running during index update, the transcript will be indexed right away. Once all transcripts are indexed during an update, the index and underlying Chroma store will be persisted to disk.
Speaking of persistence… What happens when you restart the server?
Loading an existing vector index
The server starts a background task which attempts to load an index as soon as it starts:
config = Config()
config.ensure_dirs()
store = Store(config=config, max_videos=10)
@app.before_serving
async def init():
"""Initialize the index before serving"""
# Start loading the index right away, in case one exists.
app.add_background_task(store.load_index)
This load_index() method on the vector store attempts to load the index from our configured index persistence directory:
def load_index(self) -> bool:
"""Attempts to load existing index"""
self.update_status(State.LOADING, "Loading index")
try:
save_dir = self.config.index_dir_path
vector_store = self.get_vector_store()
storage_context = StorageContext.from_defaults(
vector_store=vector_store,
docstore=SimpleDocumentStore.from_persist_dir(
persist_dir=save_dir),
index_store=SimpleIndexStore.from_persist_dir(
persist_dir=save_dir),
)
index = load_index_from_storage(storage_context)
if index is not None:
self.index = index
self.update_status(
State.READY, "Index loaded and ready to query")
return True
except FileNotFoundError:
print("Existing index not found. Store will not be loaded.")
except ValueError as e:
print("Failed to load index; collection likely not found", e)
self.update_status(State.UNINITIALIZED)
return False
If the index is loaded successfully above, I update the state to READY, which will permit the client to query the index. Otherwise, I update the state to UNINITIALIZED, indicating that an index has yet to be created.
Phew! That covers our primary server-side operations for creating, querying, updating, and loading a vector index. Now, all the client needs to do is talk to the thing! Let’s do a really quick rundown of client-side operations now.
How the client hooks into all this
The first thing my demo client does is retrieve the capabilities of the server. This will inform the client whether it is allowed to try to index Daily recordings (which will be true if a Daily API key is specified). I really suggest you go this route if you have a Daily domain with some cloud recordings on it as it’s a more streamlined flow.
Next, the client starts polling the server’s vector store status. If the vector store is in “ready” state, querying is enabled. If the vector store is in a relevant state for initialization or update, the “Index Recordings” button is enabled.
The client also polls the server for what uploads are pending indexing and shows them in the UI. This way the user can click “Index Uploads” to index the pending files that were manually uploaded to the server.
And that’s pretty much it! The client can now create a new index, update it, and query it.
Conclusion
In this post, we looked at one approach to conversationally asking questions about the contents of video recordings, including Daily’s cloud recordings and manual uploads. If you have any questions or want to share your feedback, reach out to our support team or head over to our Discord community.
]]>Here at Daily, we’re excited at the prospect of all the ways that AI can enhance video calls on the web, but one thing that’s become painfully clear: building production-ready AI apps that handle video and audio is no small feat. It can sometimes take months to get these applications and their architecture fully operational. That’s why we’ve been stoked to work with Sieve, the ultimate video and audio AI cloud service.
What is Sieve, and why should I use it?
There are hundreds of ways to utilize AI to manipulate video and audio data, but what if you had access to a whole library of AI functions and models running in the cloud? This is exactly what Sieve offers.
Users can choose from dozens of apps and pre-deployed models, such as audio enhancement, video dubbing (with lip syncing!), and transcript summarization.
With Sieve, the possibilities are endless.
Using Sieve with Daily video recordings
We built a demo featuring three examples of using Sieve functions to process Daily video recordings with incredible results, demonstrating just some of the possibilities Sieve opens up for Daily users.
The functions we selected were as follows:
- audio_enhancement – Remove background noise and improve audio quality from a recording
- text_to_video_lipsync – Accepts a video and a piece of text and then alters the recording to look like the speaker is saying the words provided.
- Video Dubbing – Translate and dub over the original video to make it look like the subject is speaking a different language. This function actually consists of four distinct Sieve functions:
To see these demos in action, be sure to watch the companion video to this blog post:
How to use Sieve functions
Applying any number of Sieve functions to your video or audio data always follows the same basic workflow.
- Upload your video or audio to Sieve
- Fetch the Sieve function of your choice
- Run the Sieve function
For example, in the case of using the audio_enhancement function:
import sieve
# Step 1: Upload your video/audio to Sieve
audio = sieve.Audio(url="https://storage.googleapis.com/sieve-prod-us-central1-public-file-upload-bucket/79543930-5a71-45d9-b690-77f4f0b2bfaa/1a704dda-d8be-4ae1-9894-b4ee63c69567-input-audio.mp3")
# Step 2: Fetch the Sieve function of your choice:
audio_enhancement = sieve.function.get("sieve/audio_enhancement")
# Step 3: Run the Sieve function (and capture the output)
filter_type = "all"
enhance_speed_boost = False
enhancement_steps = 50
output = audio_enhancement.run(audio, filter_type, enhance_speed_boost, enhancement_steps)
And that’s it! Any requirements for the input that each function accepts are clearly listed in their respective README on Sieve’s website.
Conclusion
The sky is the limit with Sieve’s AI infrastructure at your fingertips, and here at Daily, we are super excited about the possibilities this opens up for building AI-powered workflows for recorded voice and video data.
To learn more about Sieve, check out their documentation, and you can find the codebase for this demo on GitHub.
]]>Today, we’re thrilled to partner with Vapi as they launch the first omni-platform AI voice assistant API in the market.
Daily’s mission has always been to help developers build powerful real-time communications experiences leveraging the power of WebRTC. The AI platform shift is happening faster than any previous technology wave. We recently shipped a toolkit designed to power real-time AI: voice-driven LLM apps, bots and characters, video and vision features, and speech-to-speech experiences.
Leveraging Daily's global audio infrastructure & real-time AI toolkit, Vapi’s platform delivers low-latency, customizable, and reliable real-time conversations with AI, with Vapi assistants available on all platforms supported by Daily.
Leveraging voice-enabled generative AI technology at scale
Over the past few years, audio and video communications between co-workers, between service providers and clients, and between companies and customers have become an everyday experience in almost every industry. Now, voice-enabled generative AI is poised to become the norm for many kinds of operational, educational, and commercial conversations. Conversational AI will become ubiquitous.
ScaleConvo, a YC W24 batch company, is an example of an early adopter that implemented Vapi to manage thousands of AI-driven conversations for property management. “Vapi does the legwork of immediately parsing unstructured conversations, turning it into action asynchronously, while still on a voice call. It lets us focus on building. It’s like having a high-performing customer success agent at a fraction of the cost.”
Vapi in action
Tech Stack & Capabilities
Vapi is built on top of the best media transport, speech-to-text, text-to-speech, and LLM technologies available.
Daily’s global WebRTC infrastructure and extensively tuned client SDKs are key to delivering the fastest response times and the best possible output from Vapi’s conversational agents. Daily’s real-time bandwidth management and very low average first-hop latency everywhere in the world (13ms) guarantee that audio packets are delivered to the cloud quickly and reliably. High-quality audio makes possible accurate speech-to-text transcriptions, which in turn ensures that Vapi’s LLMs perform optimally.
Low latency is critical in real-time conversation applications, so Vapi uses Deepgram at the start of their response pipeline to transcribe what's said in under 300ms. Deepgram is an industry leader in both overall accuracy and the flexibility of its Speech-to-text models.
Together, these technologies form a best-in-class tech stack for powerful generative voice AI.
Adding Vapi to your site or application
It's hard to create and scale voice AI experiences that feel natural to talk to. Vapi handles the complexity of managing the voice AI pipeline & real-time call infrastructure and makes this easy. It’s as simple as:
- Write a prompt to create an assistant ("you're an assistant for....")
- Buy a phone number / Add a snippet to your website to deliver your assistant ("vapi.start()")
- That's it, your users can interact with your assistant with voice
The Vapi and Daily teams are excited to see what you build. If you have questions, or suggestions, or want to show off your real-time AI projects, feel free to post in our Discord community.
]]>With the ongoing evolution of LLM-powered workflows, the limits of what AI can do with real-time and recorded video are rapidly expanding. AI can now contribute to post-processing through contextualized parsing of video, audio, and transcription output. Some results are production-worthy while others are exploratory, benefiting from an additional human touch. In the end, it’s human intuition and ingenuity that enables LLM-powered applications to shine.
In this post, I’ll explore one use case and implementation for AI-assisted post-processing that can make video presenters’ lives a little easier. We’ll go through a small demo which lets you remove disfluencies, also known as filler words, from any MP4 file. These can include words like “um”, “uh”, and similar. I will cover:
- How the demo works from an end-user perspective
- A before and after example video
- The demo’s tech stack and architecture
- Running the demo locally
- What’s happening under the hood as filler words are being removed
How the demo works
When the user opens the filler removal web application, they’re faced with a page that lets them either upload their own MP4 file or fetch the cloud recordings from their Daily domain:
For this demo, I’ve stuck with the server framework's (Quart) default request size limit of 16MB (but feel free to configure this in your local installation). Once the user uploads an MP4 file, the back-end component of the demo starts processing the file to remove filler words. At this point, the client shows the status of the project in the app:
If the user clicks the “Fetch Daily recordings” button, all the Daily recordings on the configured Daily domain are displayed:

The user can then click “Process” next to any of the recordings to begin removing filler words from that file. The status of the project will be displayed:
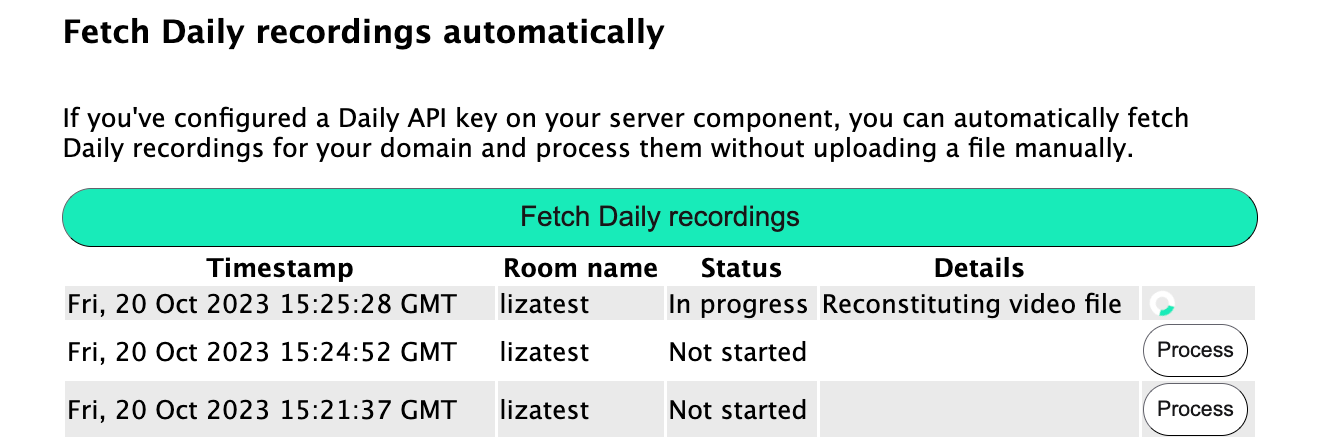
Once a processing project is complete, a “Download Output” link is shown to the user, where they can retrieve their new, de-filler-ized video:

Here’s an example of a before and after result:
Before
Before filler word removal
After
After filler word removal
As you can see, the output is promising but not perfect–I’ll leave some final impressions of both Deepgram and Whisper results at the end of this post.
Now that we’re familiar with the user flow, let’s look into the demo tech stack and architecture.
Tech stack and architecture
This demo is built using the following:
- JavaScript for the client-side.
- Python for the server component.
- Deepgram and Whisper as two LLM transcription and filler word detection options:
- Deepgram’s Python SDK to implement Deepgram transcription with their Nova-tier model, which lets us get filler words in the transcription output. This transcriber relies on a Deepgram API key.
whisper-timestamped, which is a layer on top of the Whisper set of models enabling us to get accurate word timestamps and include filler words in transcription output. This transcriber downloads the selected Whisper model to the machine running the demo and no third-party API keys are required.
- Daily’s REST API to retrieve Daily recordings and recording access links. If a Daily API key is not specified, the demo can still be used by uploading your own MP4 file manually.
On the server-side, the key concepts are:
- Projects. The
Projectclass is defined in server/project.py. Each instance of this class represents a single video for which filler words are being removed. When a project is instantiated, it takes an optionaltranscriberparameter. - Transcribers. Transcribers are the transcription implementations that power filler word detection. As mentioned before, I’ve implemented Deepgram and Whisper transcribers for this demo. You can also add your own by placing any transcriber you’d like into a new class within the
server/transcription/directory (I’ll talk a bit more about that later).
The steps an input video file goes through are as follows:
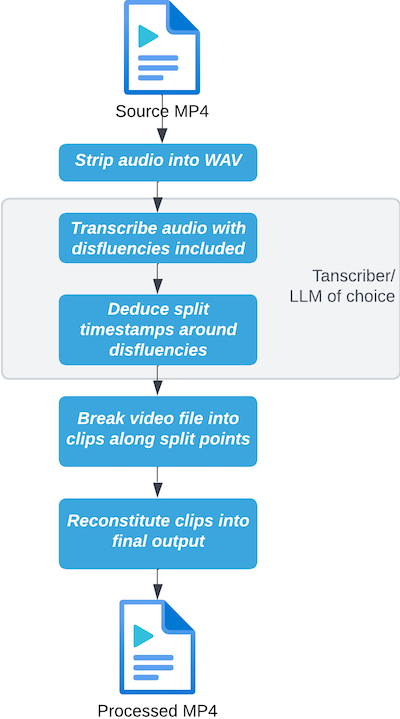
Running the demo locally
To run the demo locally, be sure to have Python 3.11 and FFmpeg installed.
Then, run the following commands (replacing the python3 and pip3 commands with your own aliases to Python and pip as needed):
# Clone the git repository
git clone https://github.com/daily-demos/filler-word-removal.git
cd filler-word-removal
git checkout v1.0
# Configure and activate a virtual environment
python3 -m venv venv
source venv/bin/activate
# Install dependencies
pip install -r requirements.txt
Optionally, copy the .env.sample file and assign your Deepgram and Daily API keys. Both of these are optional, but I think Deepgram results are usually superior to Whisper out of the box and I’d really suggest you try that out.
Now, run the following commands in two separate terminals within your virtual environment:
# Start the processing server
quart --app server/index.py --debug run
# Serve the front-end
python -m http.server --directory client
Open your web browser of choice (I suggest Chrome) to the localhost address shown in the second terminal window above. It will probably be http://localhost:8000.
Now that we’ve got the app running, let’s see what’s happening under the hood.
Under the hood of AI-powered video filler word removal
I’m going to mostly focus on the server side here, because that’s where all the magic happens. You can check out the source code for the client on GitHub to have a look at how it uses the server components below.
Server routes
All of the processing server routes are defined in server/index.py. They are:
POST /upload: Handles the manual upload of an MP4 file and begins processing the file to remove filler words.POST /process_recording/<recording_id>: Downloads a Daily cloud recording by the provided ID and begins processing the file to remove disfluencies.GET /projects/<project_id>: Reads the status file of the given filler-word-removal project and returns its contents. Enables the client to poll for status updates while processing is in progress.GET /projects/<projct_id>/download: Downloads the output file for the given filler-word-removal project ID, if one exists.GET /recordings: Retrieves a list of all Daily recordings for the configured Daily domain.
Let’s go through the manual upload flow and see how processing happens.
Processing an MP4 file with the /upload route
The /upload route looks as follows:
@app.route('/upload', methods=['POST'])
async def upload_file():
"""Saves uploaded MP4 file and starts processing.
Returns project ID"""
files = await request.files
file = files["file"]
project = Project()
file_name = f'{project.id}.mp4'
file_path = os.path.join(get_upload_dir_path(), file_name)
try:
await file.save(file_path)
if not os.path.exists(file_path):
raise Exception("uploaded file not saved", file_path)
except Exception as e:
return process_error('failed to save uploaded file', e)
return process(project, file_path, file_name)
Above, I start by retrieving the file from the request. I then create an instance of Project(), which will generate a unique ID for itself when being instantiated as well as decide which transcriber to use. I’ll cover the Project instance setup shortly.
Next, I retrieve the path to which I’ll save the uploaded file based on the newly-created project ID. This directory can be configured in the application’s environment variables - check out the /server/config.py file for more information.
Once I have the file and the path to save it to, I save the file. If something goes wrong during this step, I return an error to the client. If the file saved successfully, I begin processing. I’ll dive into the processing step shortly. First, let’s take a quick look at the Project constructor I mentioned above:
Project setup
As mentioned above, the Project class constructor configures a unique ID for the project. It also decides which transcriber (Deepgram or Whisper) will be used:
class Project:
"""Class representing a single filler word removal project."""
transcriber = None
id = None
def __init__(
self,
transcriber=None,
):
if not transcriber:
transcriber = Transcribers.WHISPER
deepgram_api_key = os.getenv("DEEPGRAM_API_KEY")
if deepgram_api_key:
transcriber = Transcribers.DEEPGRAM
self.transcriber = transcriber.value
self.id = self.configure()
Above, if a transcriber argument is not passed in, Project will look for a DEEPGRAM_API_KEY environment variable. If a Deepgram API key has been configured, Deepgram will be used as the transcriber. Otherwise, it’ll fall back to a locally-downloaded Whisper model.
The project ID is a UUID generated in the configure() method, which checks for conflicts with any existing projects and sets up the temporary directory for this project instance:
def configure(self):
"""Generates a unique ID for this project and creates its temp dir"""
proj_id = uuid.uuid4()
temp_dir = get_project_temp_dir_path(proj_id)
if os.path.exists(temp_dir):
# Directory already exists, which indicates a conflict.
# Pick a new UUID and try again
return self.configure()
os.makedirs(temp_dir)
return proj_id
Now that we know how a project is configured, let’s dig into processing.
Beginning processing
The process() function in server/index.py takes the Project instance I created earlier, the path of the uploaded MP4 file, and the file name. It then processes the project in a Quart background task:
def process(project: Project, file_path: str, file_name: str) -> tuple[quart.Response, int]:
"""Runs filler-word-removal processing on given file."""
try:
app.add_background_task(project.process, file_path)
response = {'project_id': project.id, 'name': file_name}
return jsonify(response), 200
except Exception as e:
return process_error('failed to start processing file', e)
This way, the client’s request does not need to wait until the whole filler-word-removal process is complete, which can take a couple of minutes. The user will know right away that processing has started and receive a project ID which they can use to poll for status updates.
We’re now ready to dig into the critical part: What does project.process() do?
The processing step
The process() project instance method is responsible for all of the filler-word-removal operations and status updates on the project:
def process(self, source_video_path: str):
"""Processes the source video to remove filler words"""
self.update_status(Status.IN_PROGRESS, '')
try:
self.update_status(Status.IN_PROGRESS, 'Extracting audio')
audio_file_path = self.extract_audio(source_video_path)
except Exception as e:
traceback.print_exc()
print(e, file=sys.stderr)
self.update_status(Status.FAILED, 'failed to extract audio file')
return
try:
self.update_status(Status.IN_PROGRESS, 'Transcribing audio')
result = self.transcribe(audio_file_path)
except Exception as e:
traceback.print_exc()
print(e, file=sys.stderr)
self.update_status(Status.FAILED, 'failed to transcribe audio')
return
try:
self.update_status(Status.IN_PROGRESS, 'Splitting video file')
split_times = self.get_splits(result)
except Exception as e:
traceback.print_exc()
print(e, file=sys.stderr)
self.update_status(Status.FAILED, 'failed to get split segments')
return
try:
self.update_status(Status.IN_PROGRESS, 'Reconstituting video file')
self.resplice(source_video_path, split_times)
except Exception as e:
traceback.print_exc()
print(e, file=sys.stderr)
self.update_status(Status.FAILED, 'failed to resplice video')
return
self.update_status(Status.SUCCEEDED, 'Output file ready for download')
Aside from basic error handling and status updates, the primary steps being performed above are:
extract_audio(): Extracting the audio from the uploaded video file and saving it to a WAV file.transcribe(): Transcribing the audio using the configured transcriber.get_splits(): Getting the split times we’ll use to split and reconstitute the video with filler words excluded. This also uses the configured transcriber, since the data format here may be different across different transcription models or services.resplice(): Cuts up and then splices the video based on the transcriber’s specified split times.
I’ve linked to each function in GitHub above. Let’s take a look at a few of them in more detail. Specifically, let’s focus on our transcribers, because this is where the LLM-powered magic happens.
Transcribing audio with filler words included using Deepgram
I’ll use Deepgram as the primary example for this post, but I encourage you to also check out the Whisper implementation to see how it varies.
In the server/transcription/dg.py module, I start by configuring some Deepgram transcription options:
DEEPGRAM_TRANSCRIPTION_OPTIONS = {
"model": "general",
"tier": "nova",
"filler_words": True,
"language": "en",
}
The two most important settings above are "tier" and "filler_words". By default, Deepgram omits filler words from the transcription result. To enable inclusion of filler words in the output, a Nova-tier model must be used. Currently, this is only supported with the English Nova model.
Let’s take a look at the dg module transcription step:
def transcribe(audio_path: str):
"""Transcribes give audio file using Deepgram's Nova model"""
deepgram_api_key = os.getenv("DEEPGRAM_API_KEY")
if not deepgram_api_key:
raise Exception("Deepgram API key is missing")
if not os.path.exists(audio_path):
raise Exception("Audio file could not be found", audio_path)
try:
deepgram = Deepgram(deepgram_api_key)
with open(audio_path, 'rb') as audio_file:
source = {'buffer': audio_file, 'mimetype': "audio/wav"}
res = deepgram.transcription.sync_prerecorded(
source, DEEPGRAM_TRANSCRIPTION_OPTIONS
)
return res
except Exception as e:
raise Exception("failed to transcribe with Deepgram") from e
Above, I start by retrieving the Deepgram API key and raising an exception if it isn’t configured. I then confirm that the provided audio file actually exists and—you guessed it—raise an exception if not. Once we’re sure the basics are in place, we’re good to go with the transcription.
I then instantiate Deepgram, open the audio file, transcribe it via Deepgram’s sync_prerecorded() SDK method, and return the result.
Once the transcription is done, the result is returned back to the Project instance. With Deepgram, the result will be a JSON object that looks like this:
{
"metadata":{
//… Metadata properties here, not relevant for our purposes
},
"results":{
"channels":[
{
"alternatives":[
{
"transcript":"hello",
"confidence":0.9951172,
"words":[
{
"word":"hello",
"start":0.79999995,
"end":1.3,
"confidence":0.796875
}
]
}
]
}
]
}
}
The next step is to process this output to find relevant split points for our video.
Finding filler word split points in the transcription
After producing a transcription with filler words included, the same transcriber is also responsible for parsing the output and compiling all the split points we’ll need to remove the disfluencies. So, let’s take a look at how I do this in the dg module (I’ve left some guiding comments inline):
def get_splits(transcription) -> timestamp.Timestamps:
"""Retrieves split points with detected filler words removed"""
filler_triggers = ["um", "uh", "eh", "mmhm", "mm-mm"]
words = get_words(result)
splits = timestamp.Timestamps()
first_split_start = 0
try:
for text in words:
word = text["word"]
word_start = text["start"]
word_end = text["end"]
if word in filler_triggers:
# If non-filler tail already exists, set the end time to the start of this filler word
if splits.tail:
splits.tail.end = word_start
# If previous non-filler's start time is not the same as the start time of this filler,
# add a new split.
if splits.tail.start != word_start:
splits.add(word_end, -1)
else:
# If this is the very first word, be sure to start
# the first split _after_ this one ends.
first_split_start = word_end
# If this is not a filler word and there are no other words
# already registered, add the first split.
elif splits.count == 0:
splits.add(first_split_start, -1)
splits.tail.end = words[-1]["end"]
return splits
except Exception as e:
raise Exception("failed to split at filler words") from e
Above, I retrieve all the words from Deepgram’s transcription output by parsing the transcription JSON (check out the get_words() function source if you’re curious about that object structure).
I then iterate over each word and retrieve its ”text”, ”start”, and ”end” properties. If the ”text” indicates a filler word, I end the previous split at the beginning of the filler. I then add a new split at the end of the filler.
The resulting splits could be visualized as follows:
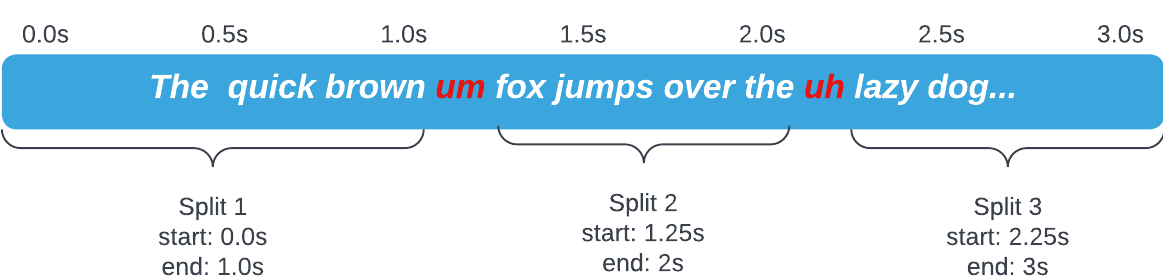
The collection of split points is then returned back to the Project class instance, where the original video gets cut and diced.
Cutting and reconstituting the original video
The remainder of the work happens entirely in the Project class, because none of it is specific to the chosen transcription API. Once we get the split points as a collection of Timestamp nodes, the project knows what to do with them in the resplice() function:
def resplice(self, source_video_path: str, splits: Timestamps):
"""Splits and then reconstitutes given video file at provided split points"""
tmp = get_project_temp_dir_path(self.id)
clips = []
current_split = splits.head
idx = 0
# The rest of the function below...
Above, I start by getting the temp directory path for the project based on its ID. This is where all the individual clips will be stored.
I then initialize an array of clips and define a current_split variable pointing to the head node of the timestamp collection.
Finally, I define a starting index for our upcoming loop. The next step is to split up the video:
def resplice(self, source_video_path: str, splits: Timestamps):
# ...Previously-covered logic above...
try:
while current_split:
start = current_split.start
end = current_split.en
# Overarching safeguard against 0-duration and nonsensical splits
if start >= end:
current_split = current_split.next
continue
clip_file_path = os.path.join(tmp, f"{str(idx)}.mp4")
ffmpeg_extract_subclip(source_video_path, start, end,
targetname=clip_file_path)
clips.append(VideoFileClip(clip_file_path))
current_split = current_split.next
idx += 1
except Exception as e:
raise Exception('failed to split clips') from e
# The rest of the function below...
Above, I traverse through every split timestamp we have. For each timestamp, I extract a subclip and save it to the project’s temp directory. I append the clip to the previously-defined clips collection. I then move on to the next split point and do the same, until we’re at the end of the list of timestamps.
Now that we’ve got all the relevant subclips extracted, it’s time to put them back together:
def resplice(self, source_video_path: str, splits: Timestamps):
# ...Previously-covered logic above...
try:
final_clip = concatenate_videoclips(clips)
output_file_path = get_project_output_file_path(self.id)
final_clip.write_videofile(
output_file_path,
codec='libx264',
audio_codec='aac',
fps=60,
)
except Exception as e:
raise Exception('failed to reconcatenate clips') from e
# Remove temp directory for this project
shutil.rmtree(tmp)
Above, I concatenate every clip I stored while splitting them and write them to the final output path. Feel free to play around with the codec, audio_codec, and fps parameters above.

Finally, I remove the temp directory associated with this project to avoid clutter.
And we’re done! We now have a shiny new video file with all detected filler words removed.
The client can now use the routes we covered earlier to upload a new file, fetch Daily recordings and start processing them, and fetch the latest project status from the server.
Final thoughts
Impressions of Deepgram and Whisper
I found that Whisper output seemed more aggressive than Deepgram’s in cutting out parts of valid words that aren’t disfluencies. I am confident that with some further tweaking and maybe selection of a different Whisper sub-model, the output could be refined.
Deepgram worked better out of the box in terms of not cutting out valid words, but also seemed to skip more filler words in the process. Both models ended up letting some disfluencies through.
Used out of the box, I’d suggest going with Deepgram to start with. If you want more configuration or to try out models from HuggingFace, play around with Whisper instead.
Plugging in another transcriber
If you want to try another transcription method, you can do so by adding a new module to server/transcription. Just make sure to implement two functions:
transcribe(), which takes a path to an audio file.get_splits(), which takes the output fromtranscribe()and returns an instance oftimestamp.Timestamps().
With those two in place, the Project class will know what to do! You can add your new transcriber to the Transcribers enum and specify it when instantiating your project.
Caveats for production use
Storage
This demo utilizes the file system to store uploads, temporary clip files, and output. No space monitoring or cleanup is implemented here (aside from removing temporary directories once a project is done). To use this in a production environment, be sure to implement appropriate monitoring measures and use a robust storage solution.
Security
This demo contains no authentication features. Processed videos are placed into a public folder that anyone can reach, associated with a UUID. Should a malicious actor guess or brute-force a valid project UUID, they can download processed output associated with that ID. For a production use case, access to output files should be gated.
Conclusion
Implementing powerful post-processing effects with AI has never been easier. Coupled with Daily’s comprehensive REST API, developers can easily fetch their recordings for further refinement with the help of an LLM. Disfluency removal is just one example of what’s possible. Keep an eye out for more demos and blog posts featuring video and audio recording enhancements with the help of AI workflows.
If you have any questions, don’t hesitate to reach out to our support team. Alternatively, hop over to our Discord community to chat about this demo.
]]>